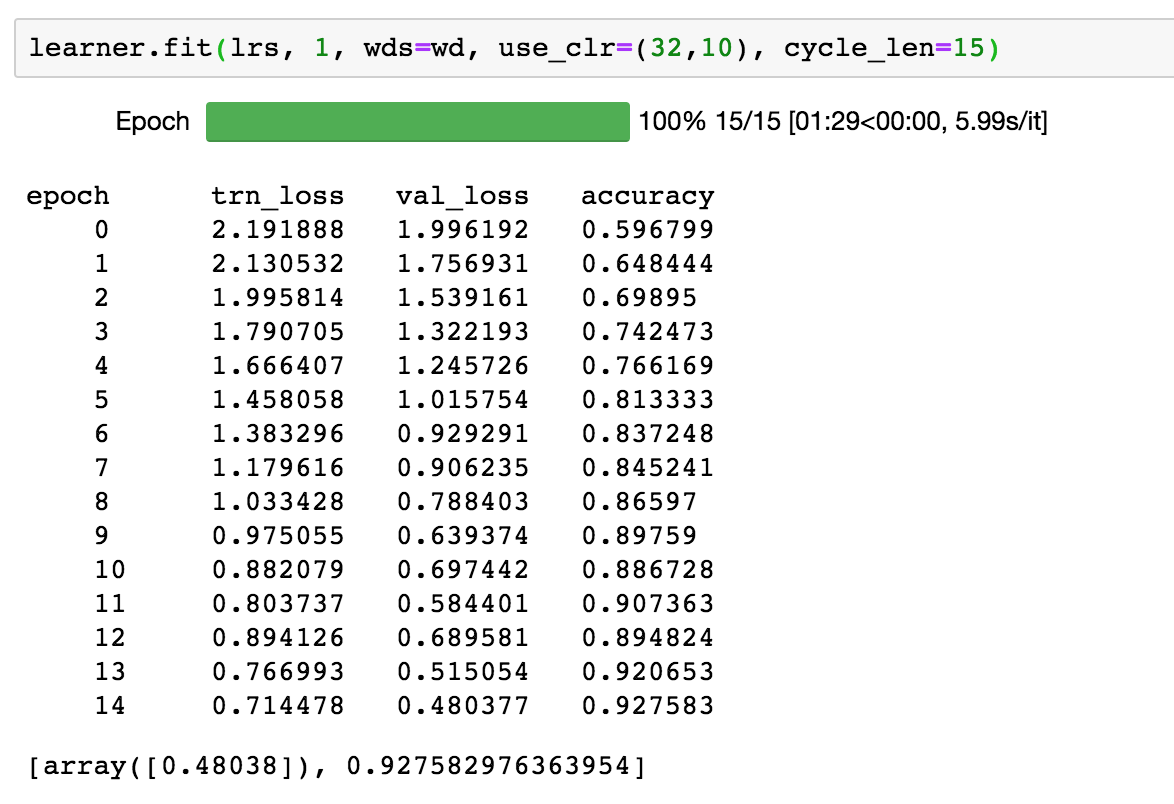
Training a language model and the accuracy is unusually high … so much so that I can’t help but feel that something is off, but I can’t ascertain what it is.
I would do a prediction on some text and look at the actual text that is generated vs the original text. If it gets about 9 out of every 10 words correct, then your accuracy would be believable. On the other hand, if the predictions are all wrong then something is wrong somewhere.
Checked the accuracy and it was ~ 93%. Check the actual predictions and they looked more like 20-25%. Had a glass of scotch, took a break, came back to the notebook and noticed this gem of a typo: