We are applying the Lesson 4 language module to our individual problems and solving various issues related to creating the text classification dataset.
2 Likes
These are the three methods we have found that can be used to convert text from various formats into a dataset.
I have implemented the Python based method described in the medium article. How do I share my notebook here?
1 Like
One way to share a notebook is to upload it to GitHub and provide a link.
@surmenok yes, figuring out how to use github, and with gist, preferably…almost there…
my notebook is here: https://github.com/Essen73/text-extract
didn’t get gist to work yet.
Regarding your issues stated in Readme:
- entire sentences are showing up as a word; individual words are not being seperated
- need to isolate title, author, affiliation, figure captions etc fields from the extracted text
For 1, I think the issue is in line 7 (not line 14). I used a different approach and it seems work. Now, you should be able to torkenize it at text level.
Niyoji-JACS2008.ipynb · GitHub
For 2, I think you can get all the paper information (title, author, etc) via the repository API. I got the title and summary via arXiv API before with few lines of code.
Hope this help. ![]()
1 Like
Thanks @Moody. This is very helpful. In line 4 how did you get the .txt file of the .pdf paper?
I used the online-covert.com to convert your pdf into .txt file. There are few symbols they cannot convert. But, I think you can add extra Unicode for special symbols.
1 Like
turns out textract itself can extract the text from pdf. no need to use pyPDF2.
saved the new notebook as rev 2 at https://github.com/Essen73/text-extract
The idx creation process from jeremy’s notebook is the tokenization? Need to review the lesson again.
1 Like
I am having trouble pip installing textract . It requires something called swig to be installed. But when installing swig I get the following error:
Could not find a version that satisfies the requirement swig (from versions: )
No matching distribution found for swig
Please tell me how to tackle these problems…
Thanks in advance…
1 Like
@Vishucyrus, I had similar issues (swig and sphinx) when trying to install on my local machine. I had ubuntu 14.04 + anaconda on a chromebook. Searching through the stack exchange etc forums, it seemed like the conflicts were with various versions of the anaconda, python etc. I thought I also saw an error msg regarding low memory or disk space. What is your configuration?
When I ran the same commands on my paperspace machine everything worked perfectly.
The instructions are here:
http://textract.readthedocs.io/en/stable/installation.html#ubuntu-debian
Also, I think textract is using optical character recognition, so it may not be the final solution but works for now.
1 Like
Thanks… @sandip . The problem was in libpulse-dev package. I installed it and everything then came in order.
1 Like
@Moody
This is how I got the loop to batch process multiple files to work. It does convert all the pdf files in the folder into txt files, but saves them in the root directory.
I think I need to use the open(os.path.join) thing to pass in the destination directory but haven’t figured out how to do it yet. Any pointers? Here is the original suggestion: https://stackoverflow.com/questions/42254418/how-can-i-apply-code-to-multiple-files-in-a-directory-as-well-as-output-files-wi
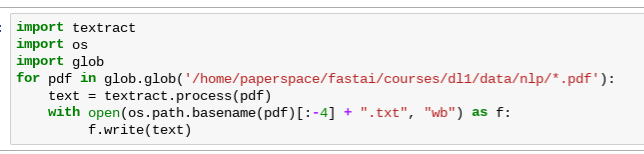
I am thinking this will help with extracting ( I need to remove or save them separately from the text of the manuscript) the title, author, affiliation, figure caption, bibliography etc fields from the papers.
How do I get started? Download the source code using wget? then what?
https://code.google.com/archive/p/pdfssa4met/
This thread has other suggestions as well: