First, thanks for creating such great courses! You are truly an inspiration.
In order to better understand the framework used in the course, I have decided to implement anything new/absent from keras/interesting in Keras/TF. That way I can validate that I am following along properly, not because I have objections to PyTorch (PyTorch is great).
Do you see any issues with me sharing my Keras/TF versions with the course participants via github? I wouldn’t want to give away any details of the course prematurely so I don’t plan on sharing it with folks outside of the course.
If it’s a simple usecase Keras would be just fine. But if you want to - Change Learning late at each layer or do any of the fancy architectures, it might be harder with keras. Whereas in PyTorch because you can put Python Print statement anywhere and understand why the network is learning or not learning, it’s much better environment for research and learning experiences.
I don’t disagree. I have a feeling the hardest part of implementing lesson 1 will be having different learning rates for different layers.
My end goal is not really to end up with a Keras implementation of the course, but to further my learning. If I can end up with a working Keras implementation I’ll call that a nice bonus
Ah…That makes sense. Sure give it a try if you have the bandwidth. It will only enhance your learning experience. But I find it really hard to even keep up with Jeremy with everything he’s sharing with us
I abandoned ResNet34 for the Keras pretrained ResNet50
I got the learning rate find function “working” (it looks ugly sometimes, but I have noticed that it’s not the smoothest on every model arch even in PyTorch)
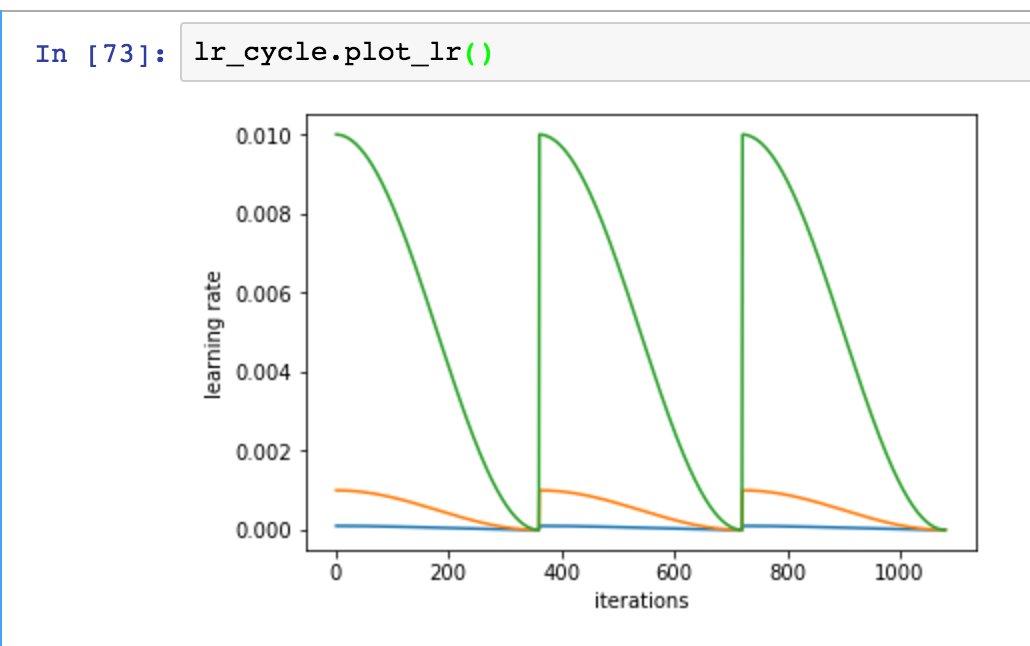
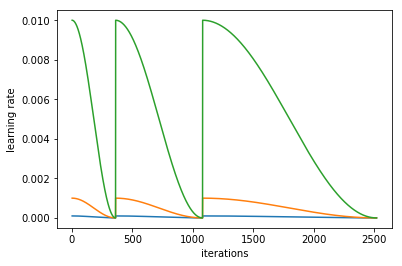
I got the cyclical learning rate working (with cosine and cycle_multi) @apil.tamang just pointed out I don’t have the ensembling in this paper so something to do later
I got the multiple learning rates for different layers working
I got the pretty learning rate plots
I wrote two different versions of a “finetune” function, one with a version of AdaptiveConcatPool2d (without the adaptive part)
Keras fit_generator/flow from directory/data augmentation code is slower than fastai’s (I had noticed this before)
I did not implement the same data normalization as fastai’s PyTorch version
Learned a lot and had fun
I am underfitting like crazy (likely due to differences in the augmentation methodology I used)
I got about 98.4% Accuracy
PyTorch > Keras for now, I am not done trying to address the underfitting and hit 99% +
Extended Version:
I started out by trying to get a version of ResNet34 implemented in Keras. After not finding a pretrained ResNet34 (only 50), I built one with as similar architecture as possible to the pretrained PyTorch ResNet34. Then I wrote a little converter to put the PyTorch model weights into my Keras model. After which, the Keras model performed extremely different than the PyTorch model. I tried rotating, flipping, etc. the weights in all combinations of directions. Afterwards, @apil.tamang reminded me that I never setout to do this…so I went back to deeplearning.
I implemented the function to find the optimal learning rate with a callback. I noticed that Jeremy had some code for early stopping that looks for a 4x jump in loss. I found that when the Loss vs. Log Scale Learning Rate plot is really noisy that increasing this number is helpful to see more of the plot.
My favorite part was getting multiple learning rates for different layers. I am still going to keep messing around with this thing and I hope some of you will give it a look too.
As always I am open to suggestions, feedback, criticism, etc.
Very nice! Try to make the API as close as possible to the fastai API, so that way it’s easy for people to move between the libraries, if your keras port ends up reasonably complete and successful…
Note that keras preprocessing by default squishes images, rather than cropping. That isn’t best practice AFAIK.
@jeremy i took a look at your Keras code for lesson 1. I think the culprit for your lack of accuracy might be RMSProp. I tried using RMS Prop and couldn’t get better than 50% accuracy. While using SGD and the techniques you applied in PyTorch I am able to get 98.5%.
Thanks for looking into it @metachi . I don’t see how any of those could be the issue, since the training set is looking fine. It seems like the issue is specific to my validation data. If you run my code with each of the changes you mention removed, does it work for you? If so, we could gradually add them back to figure out which is causing the problem.
I went back to your original code and reran it. I got ~80% validation accuracy after the last fit_generator command.
Turns out I wasn’t calculating validation acc on the fly in my code, so I added that and appear to be getting similar results as the fastai Keras model (~50% val_acc after 1 epoch, 77% val_acc after 2, and 96% val_acc after 3).
So it looks like the main difference in accuracy is likely that I go on to do cyclical learning rates and different learning rates for the different layers simultaneously (like the pytorch version, but in Keras). Whereas the fastai Keras version is only training a portion of the model with 1 constant learning rate.
This really highlights the effectiveness of these techniques (different learning rates per layer and cyclical learning rates)
I found the problem, thanks to a fast.ai alum who helped me on twitter I was using the wrong preprocessing function. Pushed a fix now. Initial training now looks fine, although after unfreezing some layers the validation set falls over at the end of training.
Thanks @jeremy ! Looks like I had the same issue with my model. It is converging much faster at the start of training, but still ultimately ends up with similar accuracy
Hey @adityak6798, I ended up putting this project down once the course really got rolling (and I realized the volume of effort it would take to properly pull it off). You are more than welcome to fork it and take a run at doing anything you want.
If you’re interested, I did end up implementing the CircularLR and CircularLR beta, but didn’t end up adding them to the repo. Happy to share those as well.