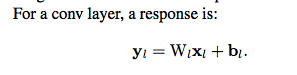Hi! Does anybody else think that backward derivation in kaiming paper is a bit awkward (wrong?) w.r.t. \Delta y having size k^2d and \hat{W} being c-by- k^2d ?
c - num of input channels
d - num of output channels (i.e. filters)
k - kernel size
On forward pass you do: W @ x = (d, k^2*c) @ (k^2*c,) = (d,) - d channels of output pixel. For c=3, k=3 and d=10 we take 27 input pixels and produce 10 channels of output pixel. Makes sense.
On backward pass according to paper you do: W_hat @ delta(y) = (c, k^2*d) @ (k^2*d,) = (c,) - c gradients of input pixel. So with the example above for c=3, k=3 and d=10 we take 90(!) output gradients, multiply them by some 90 weights and produce only(!) 3 input gradients. Doesn’t make sense to me. Am I missing something?
In forward pass we got one pixel of d channels as output. So why then delta(y) is size k^2d and not just size d in backward? Shouldn’t backward pass be: transpose(W) @ delta(y) = (k^2*c, d) @ (d,) = (k^2*c,) to get back gradients of original k^2c input pixels? So for c=3, k=3 and d=10 we take 10 output gradients (one for each channel we output in forward pass) and produce 27 input gradients (one for each input pixel used).
I imagine that k^2d size of delta(y) somehow reflects the fact, that each of many (but not all!) input pixels is used in k^2 output pixels (for stride=1 convolution). So in backward phase each such pixel accumulates its gradient from k^2 output pixels, each piece being a sum of d products. That’s how (it seems to me) you get \hat{n} = k^2d.
But if previous statement is true, then Kaiming’s \hat{n} equals k^2d only for stride=1 convolutions where kernel size is non-significant compared to image size. Whereas for say k=3 stride=3 convolution \hat{n} = d instead of \hat{n} = k^2d because each input pixel is used only in 1 output pixel. Same for convolutions where image size is equal to kernel size, since each input pixel is again used only once. If kernel size is not too small compared to image size, \hat{n} will be something between d and k^2d.
Has anyone else bothered with this? I’ve read @PierreO blog post about inits, but there definition of \hat{n} is kinda skipped.