Yeah the dataset is quite large actually … I got 0.9616 with resnet34 … and the network is still underfitting so a little bit more should be possible with it. Do you use TTA and data augmentation?
Yes I did. I’m also underfitting and I think there’s room for improvement. Also evaluation says that you only have to look in center 32x32 patch of image which I totally ignored.
I’m trying this competition too for practice during DL1. Can I ask what you set metrics to? The evaluation page says to use ROC, so my first attempt was just to do:
from sklearn.metrics import roc_curve
metrics = [roc_curve]
However, as soon as it tried to go through the validation set, I got the error:
ValueError: continuous-multioutput format is not supported
This was inside roc_curve. Not sure how to proceed. Try to workout why it’s not working, or am I just using the wrong metrics? Any help would be much appreciated.
I just used accuracy as it works good enough in this case(training data is not skewed) I’ll report how it fares with roc scoring later though. Also the metric should be
from sklearn.metrics import roc_auc_score
Not totally sure though. ROC is just a curve, the metric is the area under that curve.
OK, thanks a lot. Still a newbie in applying Fast.ai to new problems.
The metric you suggested gave the same error. I guess the issue is that it isn’t suitable for the live calculation of the status updates. However, I guess I can also feed in the predictions and the ground truth manually after training to get the same metric as the Kaggle competition.
I believe you could write your own wrapper for roc_auc_score that takes in the same arguments like accuracy. I’m not sure whether we feed in the actual probabilities or the predictions in the validation step of the training loop
I believe you could write your own wrapper for roc_auc_score that takes in the same arguments like accuracy .
Not possible. ROC-AUC is computed using a changing threshold. If you feed it probabilities, the threshold is defined as the minimal probability that you’ll tag as positive. So a sample for which the model assigned a probability of 0.56 will be classified positive with a threshold of 0.5, and negative with a threshold of 0.6. Each point on the ROC curve corresponds to a specific threshold, and the ROC-AUC score is the area underneath the curve. So basically you have to pass continuous values to compute the ROC-AUC, not predictions.
I have been using as a training metric:
def auc_score(y_score,y_true):
return torch.tensor(roc_auc_score(y_true,y_score[:,1]))
But I merely used the ROC computation from a Kaggle kernel without fully understanding the ROC measure.
Is there a correct way to simulate Kaggle’s scoring using our own validation set? My validation AUROC measure is always much higher than Kaggle’s (on their test set).
Well, if I understand you correctly, you wish to asses your trained model’s ROC-AUC on your own validation set. If that is so, you need to use your model and predict probabilities for the validation set.
Then, the only thing you need is:
from sklearn.metrics import roc_auc_score
roc_auc_score(y_true, y_proba)
Here I assume y_true is the correct labels, and y_proba is you model’s probability predictions on the validation set.
Thanks for responding. Yes, that is exactly the formula I am using. The mystery is that ROC-AUC on validation set is .99, while Kaggle’s score on test set is .94. I have made sure there’s no leakage of validation set into training set.
Thanks for taking a look. I re-trained 3 epochs from the beginning in order to make sure there is no mixing of datasets. Validation set is 20% of training images.
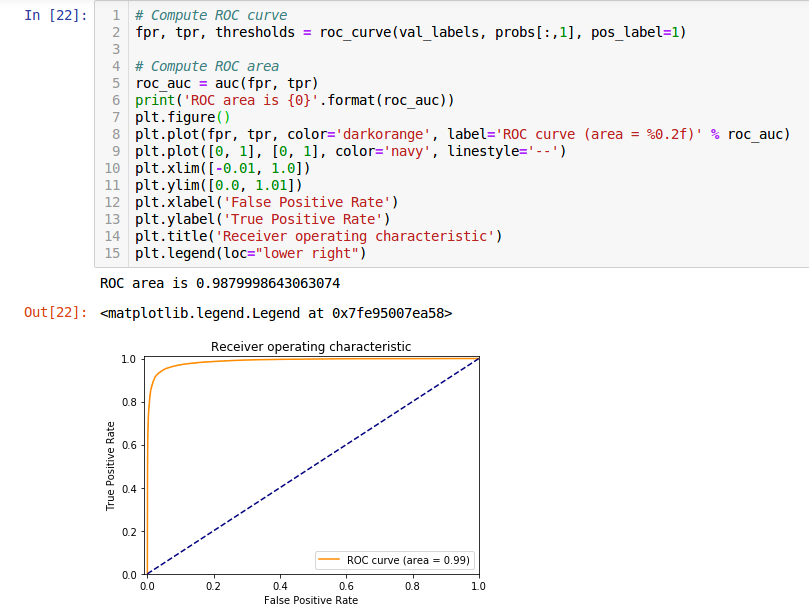
Here are my accuracy and ROC computations:
def auc_score(y_score,y_true):
return torch.tensor(roc_auc_score(y_true,y_score[:,1]))
# Predict the validation set
probs,val_labels = learn.get_preds(ds_type=DatasetType.Valid) # Predicting without TTA
accuracy(probs,val_labels), auc_score(probs,val_labels)
Out: (tensor(0.9523), tensor(0.9880))
Here is submission to Kaggle:
testprobs,test_labels = learn.get_preds(ds_type=DatasetType.Test) # Predicting without TTA
testdf = data.test_ds.to_df()
testdf.columns = [‘id’,‘label’]
testdf[‘label’] = testprobs[:,1]
testdf[‘id’] = testdf[‘id’].apply(lambda fp: Path(fp).stem)
testdf.to_csv(SUBM/‘rocTest.csv’, index=False, float_format=’%.9f’)
Kaggle score = 0.9478, 4% lower than the AUROC calculated from my local validation set.
Here is ROC computation and graph (I copied this code):