Hi is anyone into the https://www.kaggle.com/c/facial-keypoints-detection contest?
I am playing with the data but I still don’t see the right way of training a model in the “fast ai” way.
First of all the contest is dealing with images. But the images come in csv files (list of raw 1-channel pixels in a csv column). The training set is about 7k images with 30 labels per image (e.g. left_eye_center_x left_eye_center_y right_eye_center_x right_eye_center_y, etc)
So to be able to use the existing fast.ai image processing tools with little effort I first wrote a little script to put all the images in the filesystem as jpg images …
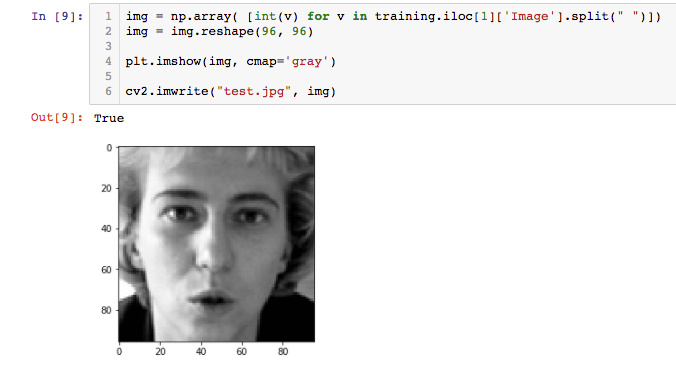
Then I want to create a mapping in a csv file to map the filename with the labels (30 labels x,y coordinates of center_left_eye etc, nose, etc). Not all labels are set for each image (eg. when you turn your head slightly to one side you dont see one ear etc.) All images are 96x96 so I can easily normalize the coordinates to a range between 0-1 … ok so far …
So, this is not a classification but a regression problem. I have 30 label-classes (some maybe empty) and the values inside are not “class-labels”. I have checked the source code of fastai/dataset.py and in class ImageClassifierData I find the comment:
@classmethod
def from_csv(cls, path, folder, csv_fname, bs=64, tfms=(None,None),
val_idxs=None, suffix='', test_name=None, continuous=False, skip_header=True, num_workers=8):
""" Read in images and their labels given as a CSV file.
This method should be used when training image labels are given in an CSV file as opposed to
sub-directories with label names.
Arguments:
path: a root path of the data (used for storing trained models, precomputed values, etc)
folder: a name of the folder in which training images are contained.
csv_fname: a name of the CSV file which contains target labels.
bs: batch size
tfms: transformations (for data augmentations). e.g. output of `tfms_from_model`
val_idxs: index of images to be used for validation. e.g. output of `get_cv_idxs`.
If None, default arguments to get_cv_idxs are used.
suffix: suffix to add to image names in CSV file (sometimes CSV only contains the file name without file
extension e.g. '.jpg' - in which case, you can set suffix as '.jpg')
test_name: a name of the folder which contains test images.
**continuous: TODO**
skip_header: skip the first row of the CSV file.
num_workers: number of workers
So the continuous part what I probably would need for this is a TODO. So I think I have 2 options. First implement the continuous Part in the fast.ai library (but I can’t estimate how hard/much effort this is). Or second somehow build my own dataloader for multi-label regression tasks on image data …
Can anyone give me a hint on what next steps you would take from here?