I am trying to understand Kaggle’s evaluation mechanism. I looked at redux’s evaluation page and kaggle’s main evaluation page. The main driver for me was to understand what value of clipping is the ideal. I was curious why higher accuracy is not better and tried out following variations:
Clipping, log accuracy:
0.001 = 0.15953
0.01 = 0.11605
0.05 = 0.11954
It was not clear to me if retaining prediction accuracy is a good or a bad thing with given data points, as 0.01 turned out to be better than 0.001 and 0.05
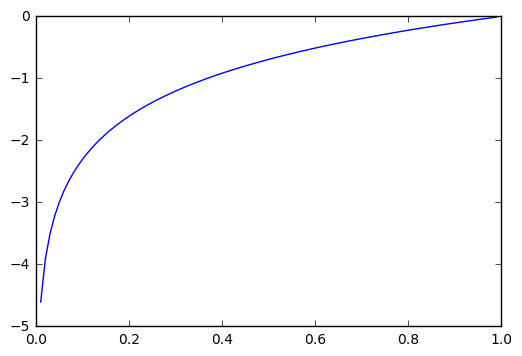
Here is the plot of logx
From this graph I infer that lower probabilities are penalized the most which aligns with what kaggle page mentiones about higher probability wrong predictions are penalized the most.
So here are some questions/thoughts:
What is the loss function keras calculates for each epoch. If it is not log loss by default, can we change it to log loss, so that it is in line with Kaggle?
It might be worth looking at examples where we were confidently wrong and focusing on fixing those or being less confident.
Seems like a big clipping will help when our accuracy is low, but eventually it will not help as we have very few negatives?
I came across Laplace smoothing, should we consider something like that which would make the model less certain?
Thinking more about it, it seems like log loss actually makes sense in the real world. We would want to trust the model and ideally model should admit that it cannot figure out instead of being confidently wrong. Do you guys also think log loss is a better metric?
Yes, there are cases when accuracy is a misleading metric. For example, as is often the case in medical imaging, when 99 out of 100 images are healthy, you can have a naive model that simply guesses healthy and it would be accurate 99% of the time. Thus, other metrics like log loss and area under the ROC curve are deemed more appropriate for those types of problems.
Log loss is a great metric, and it is what keras uses by default - it’s another name for cross entropy loss. @brendan kindly created this page that explains more about this metric: http://wiki.fast.ai/index.php/Log_Loss .
Laplacian smoothing is where you add 1 to the denominator of count-based methods, such as naive bayes. I can’t see how it would be relevant to a deep learning approach - did you have something in mind here?
Your suggestions about clipping and looking at confidently wrong examples are good approaches.