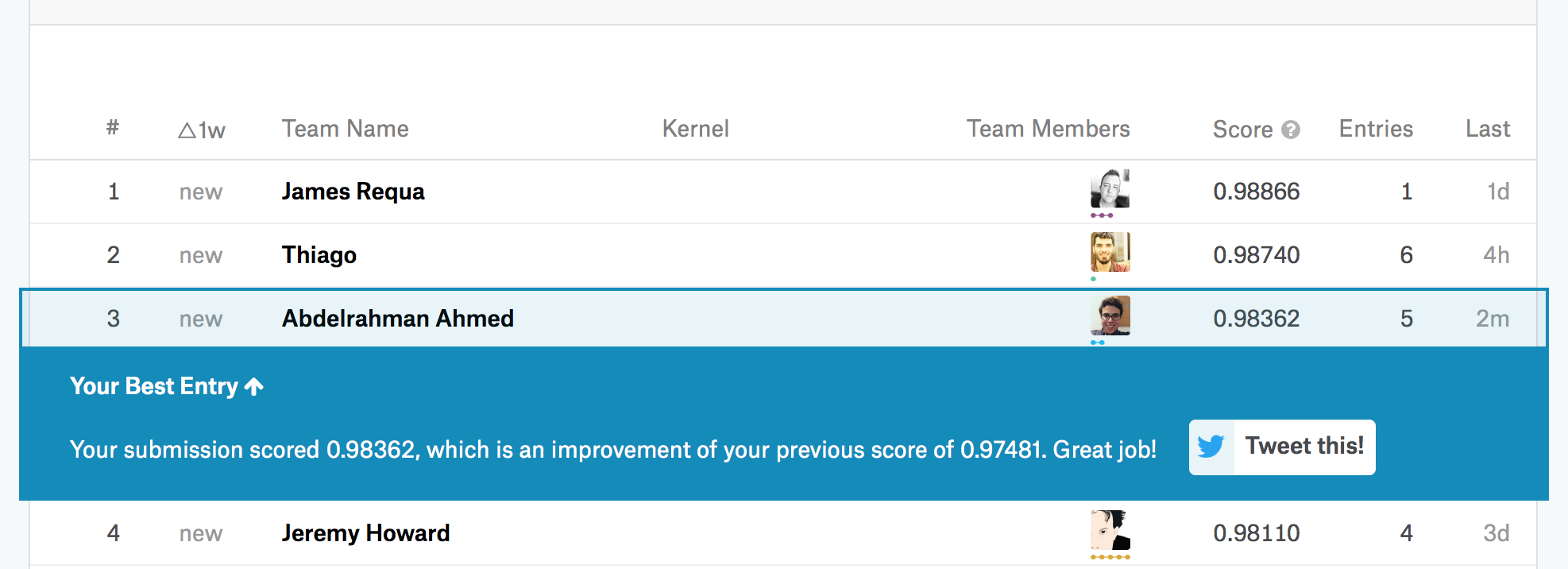
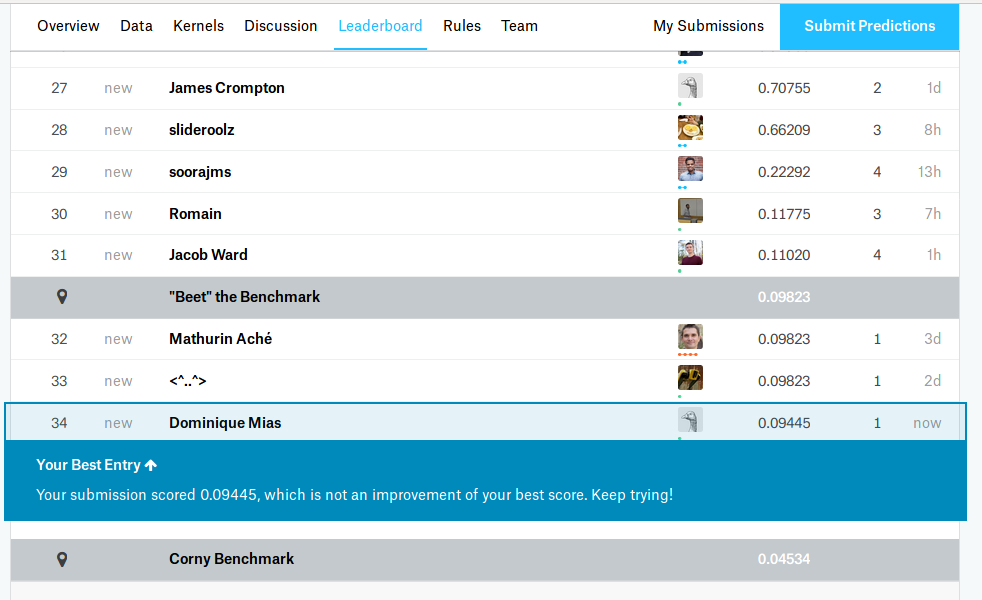
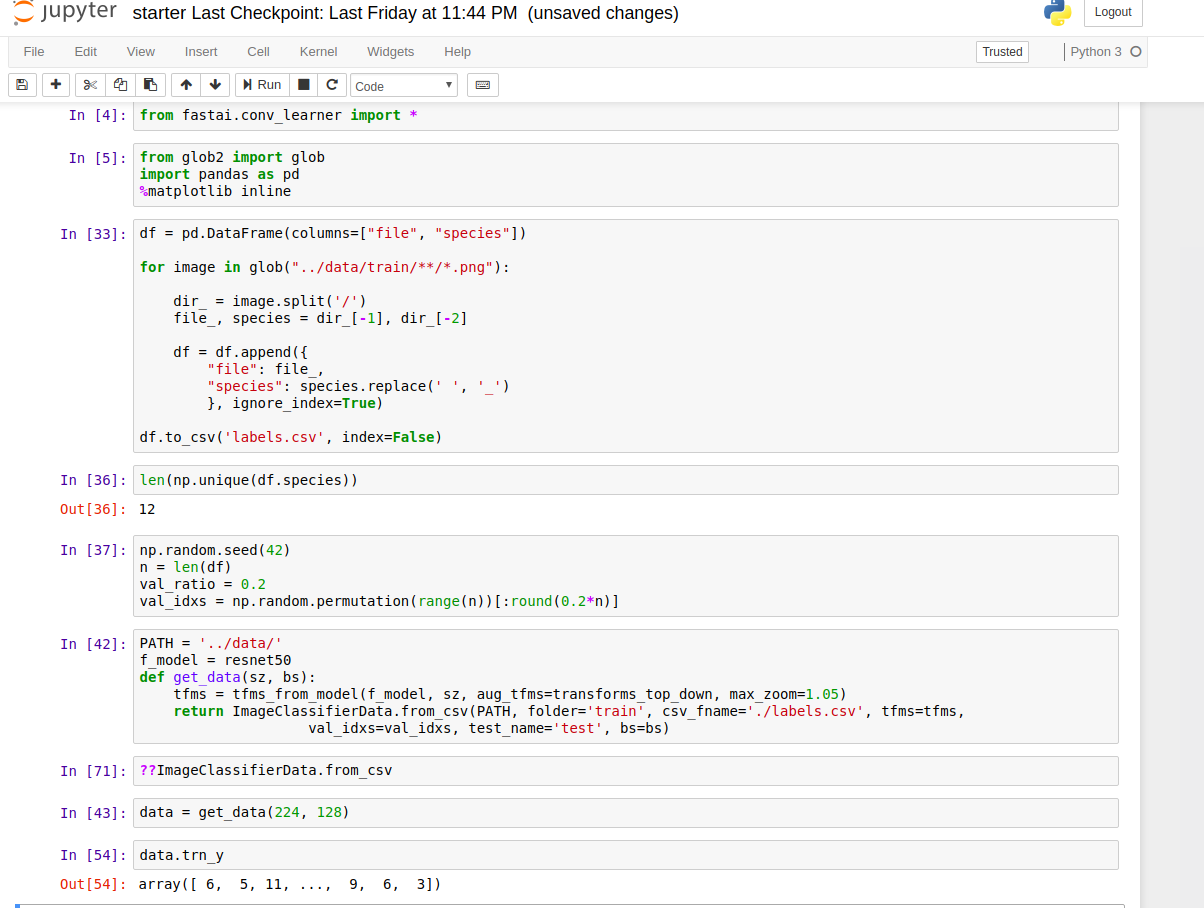
I got 96% accuracy, using resnet50 (based on comments here) and using all of the techniques i know (including resizing images and a final training step of removing the validation set). I’ll go through tomorrow and see if I missed anything from the lectures.
I have a ton of questions (apologies for so many at once):
I had an issue with my model where it appeared it was “overfit” pretty early on in my training process. Does it make sense in this case to discard your model and restart your training? I wound up with what looked like overfitting in step 3 of 7 that I did and model showed “overfit” numbers the rest of the way through my training steps. I figured the model would eventually “correct” itself, I’m not confident if this was the right approach.
I noticed that the model seemed to make it’s biggest improvements when unfreezing and training earlier layers. Intuitively, this makes sense since the image set is quite different from image net. I thought perhaps I should put some more training epochs into the earlier layers than what I wound up doing. How often do you adapt your training procedure based on this sort of in-training observation?
Finally, with discarding the validation set, is there any heuristic as to how to decide how much training to do? Since I can’t compare training with validation, I can’t tell if the model is overfitting or not. I was pretty conservative and only did 1 training step
learn.fit(.1, 3, cycle_len=1, cycle_mult=2)
I thought to possibly unfreeze and train earlier layers as well discarding the validation set because that seemed to work better for the model but I didn’t wind up doing it.
Finally, since the model seemed to overfit pretty quickly, is this at all because the training set is pretty small (iirc, 4500 images over 12 categories) and should we tweak number of epochs based on training set size?
Looks like the key in this competition is to be able to unfreeze and train some of the earlier layers. Reducing the batch size to 32 was able to get over my OOM issues.
Thanks, Jeremy. This is my first time to put an end-to-end notebook together (from data preparation to submit a csv file… although it is very hacky). Now, I can start training the model with full dataset and other basic experiments.
@jeremy Are you going to teach cross-validation and ensemble anytime soon? How can we do it with fastai library?

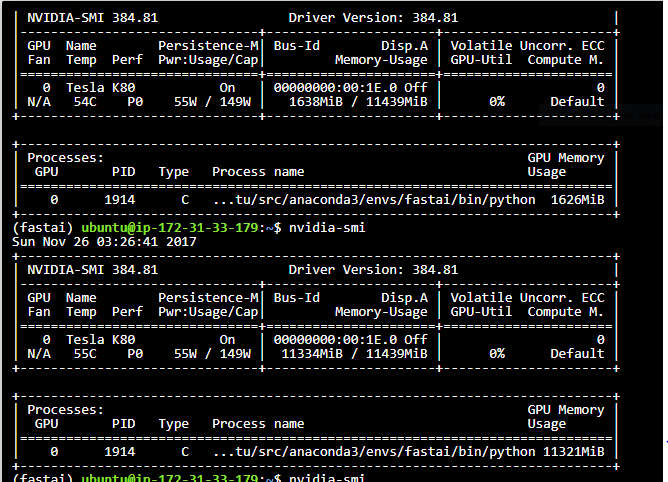
 Now, I can start training the model with full dataset and other basic experiments.
Now, I can start training the model with full dataset and other basic experiments.