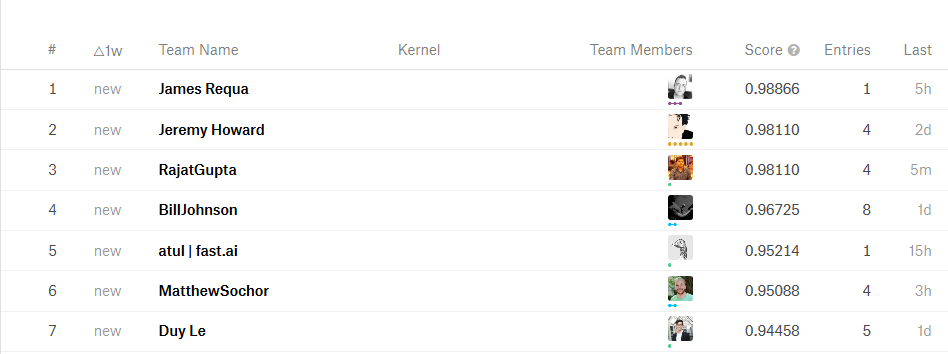
I cannot believe it 10th place 

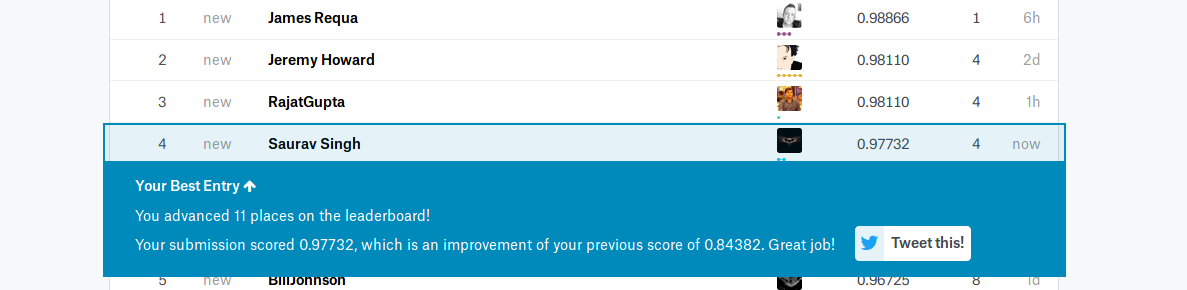
I have been using Kaggle for 2 years and this is the first time that I can accomplish this
Thanks @jeremy
I cannot believe it 10th place
I have been using Kaggle for 2 years and this is the first time that I can accomplish this
Thanks @jeremy
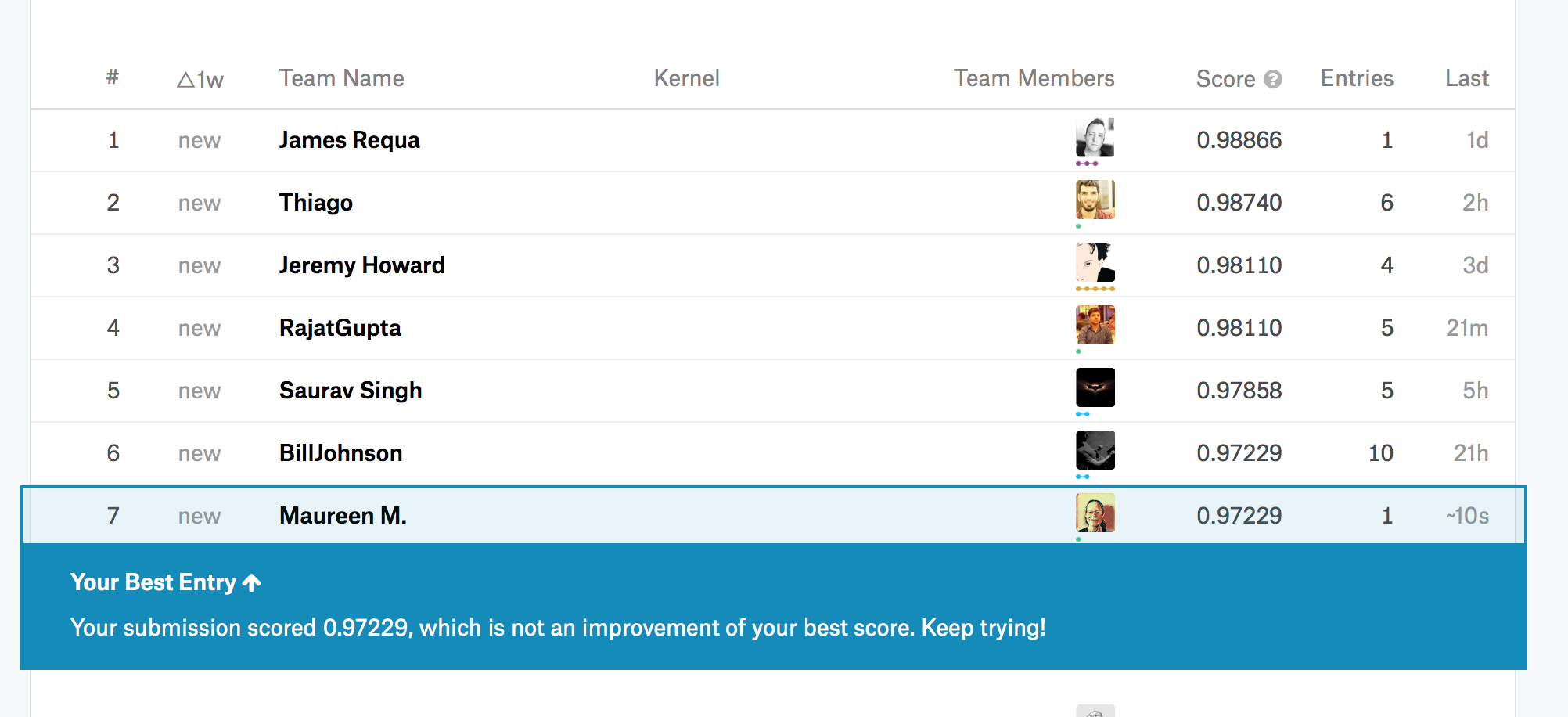
Just there. Thanks @jeremy
Yup Can’t believe it either Thanks @jeremy and @jamesrequa
So top 4 is officially fastai students and community.
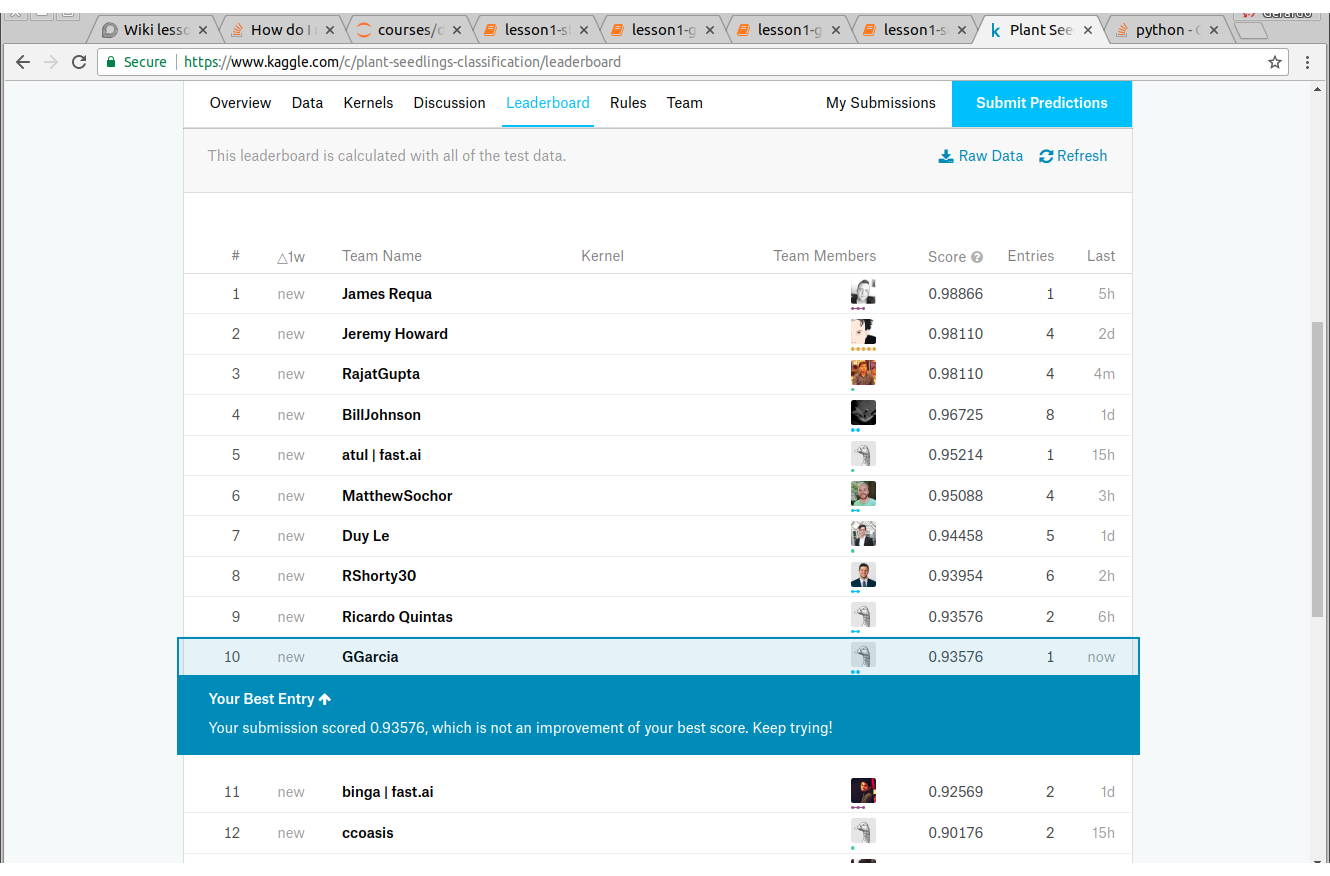
This I didn’t even used the whole training set…I think i can still get a bump using Kstratified CV
and using my full training set.
Hi,
Can someone share the accuracy / top 1 error rate for their model?
Regards
Here’s mine:
best validation loss 0.08718
best accuracy 0.97656
Should we remove all the folders in the train/folder and extract their files together and then use from_csv
Keep the images, remove the folders.
@ecdrid: Yes, first move all the images to the parent folder i.e train.
user@computer:~/fastai/courses/dl1/data/plant-seedlings-classification$ mv train/**/*.png train
and then, remove all the species folders:
user@computer:~/fastai/courses/dl1/data/plant-seedlings-classification$ rm -r train/**/
Getting the following traceback
/io/opencv/modules/imgproc/src/color.cpp:10606: error: (-215) scn == 3 || scn == 4 in function cvtColor
The notebook is attached
https://nbviewer.jupyter.org/github/AdityaSoni19031997/Machine-Learning/blob/master/Untitled.ipynb
How to fix this??
PS-:Can someone confirm whether the following directory structure is correct or not?
~/data/planet/
test train labels.csv
test - containing files as it is downloaded
train - containing files from all species folder(species folders removed)
labels.csv(mapping of training image names to classes)
/io/opencv/modules/imgproc/src/color.cpp:10606: error: (-215) scn == 3 || scn == 4 in function cvtColor
Are you sure you have deleted the species folders after moving the images?
The errors says that cvtColor with the COLOR_BGR2RGB expects an image with 3 or 4 channels, but got something different. Most likely, you haven’t deleted the folders.
Also, when you create labels.csv, do replace the relevant part with the following:
df = df.append({
"file": file_,
"species": species.replace(" ", "_")
}, ignore_index=True)
There are spaces in the species name. Replace them with underscores.
And, when you finally generate predictions and submission file, do the reverse:
log_preds_test = np.argmax(log_preds_test, axis=1)
preds_classes = [data.classes[i].replace("_", " ") for i in log_preds_test]
probs = np.exp(log_preds_test)
submission = pd.DataFrame(preds_classes, os.listdir(f'{PATH}test'))
According to the docs…
suffix: suffix to add to image names in CSV file (sometimes CSV only contains the file name without file
extension e.g. '.jpg' - in which case, you can set suffix as '.jpg')
I shouldnt pass suffix then as the labels files has it
This solves the problem…
Hi,
I was looping through the dataset and I see that the image sizes are varying a lot (49 to 3000+) . I need to scale them. torchvision.transforms.Resize is not working. What is the strategy to handle this? Border padding or thumbnail transformation?
fast.ai does that for you
resize(sz*1.3)
Mine was.
best validation loss 0.12573
best accuracy 0.95814
You don’t need to do that - that’s just a time saver. The best way is to use fastai lib transforms. We don’t use torchvision. See any of the lesson notebooks for lots of examples. We’ve been using sz for the size variable BTW.
What happen with the size?
The seedlings images are 1380x1380 pixels
The model from cats and dogs is 224x224.
What’s the best way to tackle this issue?
When I changed the sz=1380 the whole model never finished until I had to stop the whole notebook.
You can set sz to any size you want and all of the images will be resized to that same consistent image size. Personally, I tried both 224x224 and 300x300.
@jeremy got you! =D
When I put the conffusion matrix
plot_confusion_matrix(cm, data.classes)
Something like this shows up
[[ 54 0 0 0 5 0 4 0 0 0 0 0]
[ 1 189 0 0 0 0 0 0 0 0 0 0]
[ 0 0 85 0 2 0 0 0 0 0 0 0]
[ 0 0 0 403 1 0 1 0 4 2 0 0]
[ 0 0 0 0 21 0 0 0 0 0 0 0]
[ 2 4 0 1 3 265 0 0 0 0 0 0]
[ 63 0 0 0 1 0 387 1 2 0 0 0]
[ 0 0 0 0 0 0 0 21 0 0 0 0]
[ 1 0 2 9 0 0 0 0 301 3 0 0]
[ 0 0 0 0 0 0 0 0 1 30 0 0]
[ 0 0 2 0 0 0 1 0 0 0 293 0]
[ 0 1 1 2 12 0 1 3 0 0 0 165]]
I would like to run the model only on those elements that are out of the diagonal

I’m not looking for answers I’m looking for guidance on best practices to analyze those cases and try to fix them if possible.
I hate you all! ![]()