Hey guys, is anyone working on the Jigsaw Toxicity Classification kaggle competition? If so have you found fastai to be useful? I’m thinking of following some of the public kernels of using pre-trained embeddings and a simple RNN like this one, but using a fastai RNN on top of the model, but I’m not too sure how to create a databunch using the pre-trained embeddings. Does anyone have any good ideas? 
Hi,
I am working on this competition. I have tried fast.ai but it throws errors for me for now.
I also joined this competition. I am still quite novice in this field and try to learn all the basics now. But I have a question:
I saw an example of kernel that uses Fast.ai library: https://www.kaggle.com/kunwar31/simple-lstm-with-identity-parameters-fastai
But it just uses word embedding and not Transfer learning model as Jeremy presented in his lectures.
May be using pre-trained model can bring better results? Although, I do not know If it is permitted by conditions of this challenge.
Also this solution seems not use fit_one_cycle() training mechanism.
If someone interested we may join as a team for this competition.
There is a 2 hr kernel limit in the competition. From from what I have seen the usage of word2vec and simpler lstm models are a result of that. doing transfer learning with awd-lstm probably takes way longer to train on limited compute power
I still did not understand fully from this kernel limit of the competition, if it is possible to upload additional pretrained models and use them in the solution?
I also saw some discussion in the Kaggle forum which says that kernel time limitation is for inference process and not for training. I do not know if it is right.
I believe that you can train off of Kaggle and then only do the inference step in the kernel that you commit. I’ve been attempting to train a head on top of the wiki-text AWD_LSTM pre-trained model, and then upload that to kaggle, but I have no idea how to actually access the model from the kernel in order to do inference.
I think you can download the trained model as a private data set to the kernel.
And then upload it from the code.
I am trying to experiment with the similar approach now.
Fast.ai Tokenizer seems to be so slow.
If you like to participate in this competition we can combine our efforts.
So what I ended up doing was just taking my submission.csv from my jupyter notebook. Making that a new dataset on kaggle. Adding the competition data and then running the Kernel that would read the .csv and the create a new submission.csv for the output. I was/am much more curious on how I was doing than actually worrying about the placement I was getting. If for some reason i was in a medal position i would have fixed the submission or simply removed my submission. Not to worry I got a .49 score, which was disappointing to say the least.
I wasn’t sure what to do with the Target as it would throw me an error with it being in a percentile form. So I changed it to a zero or a one on the threshold
X_train.target = X_train.target.apply(lambda x: 0 if x <=0.5 else 1).copy()
This might be what caused such a poor result. What I did was take the data and make a Language model that got
training loss: 3.842373 validation loss: 3.827752 accurary: 0.316735
I then took that encoder and made a classifier, but like I said the results were terrible. I am not sure if the change of the target made the biggest difference or not because my final result was

I added a call back for AUROC and re-ran the model and I got the following:
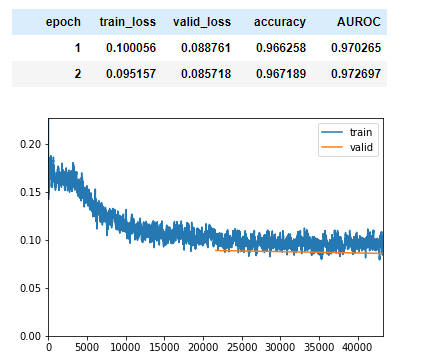
The model was really confident on it’s predictions. It was a great learning experience, but if I see something here on this thread that makes me want to go back and try again I most def will. Let me know if you think changing the target from 0 to 1 was the right idea.
Update:
So I ended up with a .92 something on the public leader board I am happy with this there a couple things that I would change the bptt. I am not sure to what or I would change the length of the sequences in the comments. Maybe changing the max_len to 200 something. Possibly doing some more pre-processing on the data for odd characters in the data set. Looking at the Kernels there has been some extensive pre-processing to the data. Jeremy states in his courses that getting rid of things off the bat is never the best idea and so i followed that advice, but he does say to get rid of the things that just shouldn’t be there. Since I am just doing this to learn I am probably not going to go back and change much. I would also look more into the loss function there is some interesting things on the kernels. I am pretty sure treating this as a toxic or not wasn’t the right way of going about this.
The piece where i messed up was the
test_preds = learn.get_preds(DatasetType.Test, ordered=True)
If you don’t put ordered true you will get the predictions out of order. The next thing I am going to do is either move on to another data set or competition
Max,
Do you know what to do with the target variable as it is in percentile form. Did you see anything on the kernels on how to make this a classification problem or is this not supposed to be a binary class?
See my message above, but i did change it to a 0 and 1 and it was pitiful results, but i am wondering if that is merely because of that.
Hello Jeremy:
I don’t think your results are bad because you converted to 0,1. See the benchmark kernel does this also:
https://www.kaggle.com/dborkan/benchmark-kernel
I am also competing on Jisaw, let me know if you would like to team up.
I managed to up load and train ULMfit for this competition, but I am getting meh scores too. Wonder if we would need to split the classes up from just binary?
Hi Jdemlow,
Can I ask you where you have finish your training?
I used the colab and try to follow the process which Jeremy has present.
But I met the problem when I try to save the databunch.
I used
#For the LM
TextDataBunch.from_df(path,train_df=X_train,
valid_df=X_valid,test_df=df_test, label_cols='target', text_cols='comment_text')
#For the data bunch
(
TextDataBunch.from_csv(path, 'train_target.csv', valid_pct=0.1, vocab=data_lm.vocab,
text_cols='comment_text', label_cols='target', test='test.csv')
)
If you used that I am not sure where your problem is coming from.