Hi all,
What is the difference between item_tfms and batch_tfms? I am confused whether all images are first cropped out (say randomly) for every epoch, using item_tfms, and then batch_tfms is applied to a batch of such cropped image? or is a batch chosen first, transformed using batch_tfms, and then all are cropped out using item_tfms? What is the correct order of processes?
In general, what is the idea behind having batch transforms and item transforms as two separate processes?
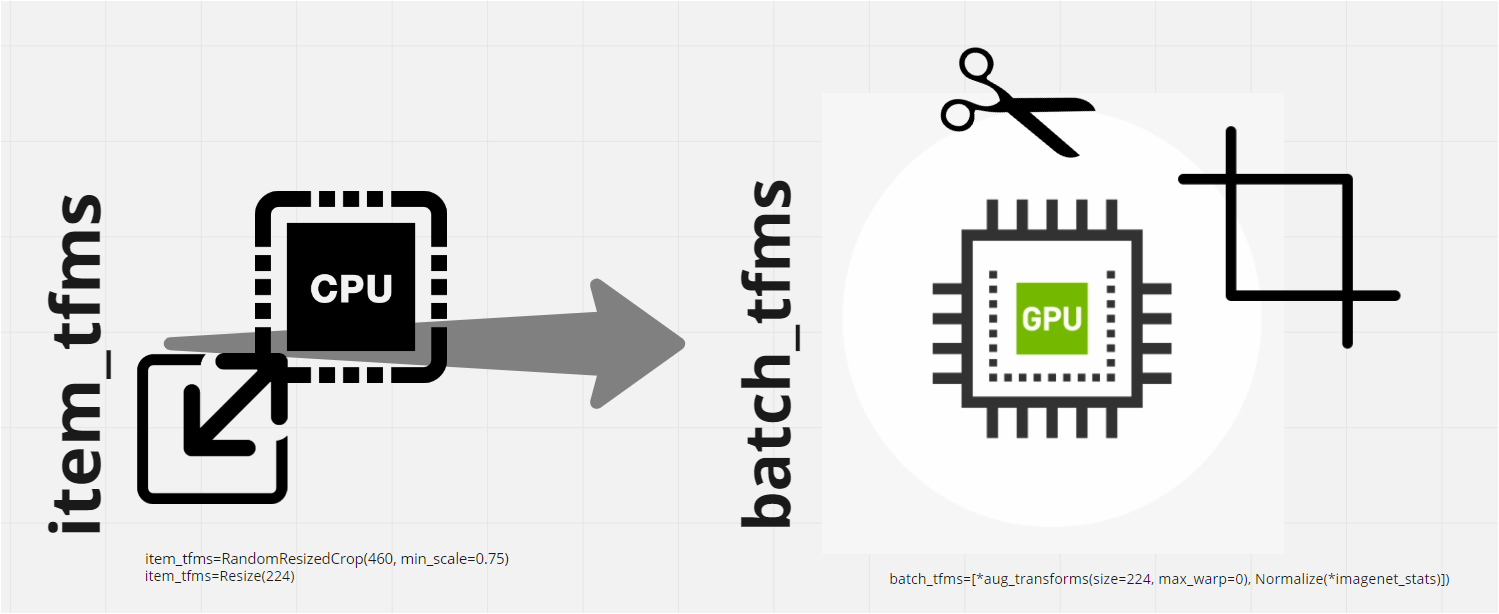
My understanding is as follows. item_tfms happens first, followed by batch_tfms. This enables most of the calculations for the transforms to happen on the GPU, thus saving time.
The first step item_tfms resizes all the images to the same size (this happens on the CPU) and then batch_tfms happens on the GPU for the entire batch of images.
If it weren’t to happen in two steps, then all these calculations would have to be done on the CPU, which is slower.
Would that be a correct explanation, @muellerzr?
So, is the advantage in terms of speed? or in terms of flexibility? or something else? And how is it advantageous over fastai v1? And what can fastai2 do that fastai1 couldnt do (in terms of transformation method)?
It’s extremely faster. You’re utilizing the GPU so it’s multitudes faster. Along with this, our Pipelines also allow us to control when and how certain transforms are done (to your discretion)
Just to clarify: both item_tfms and batch_tmfs take place each time an item and a batch is called?
So for example, if I RandomCrop and image to a smaller size than the original image, I will likely get different parts of the images in different steps in training?
Can anyone answer this question? It seems reasonable that batch_tfms is done in each epoch. Is that also the case for item_tfms? Or is item_tfms a one-time thing?
I agree that the distinction between item_tfms and batch_tfms beyond the former running on the CPU and the latter with batches on the GPU is unclear. One might naively ask why all the transforms can’t be run on the GPU (my understanding is that item_tfms mainly make sure the input data is of the same size so that it can be collated in batches, but this isn’t clear in the documentation).
Fastai is as much (if not more) about simplicity than efficiency and v1 was much more straightforward wrt data augmentations so this change needs further explaining. For example, there is a class FlipItem (for item_tfms) and a class Flip (for batch_tfms). This is confusing.
So far I do understand that item_tfms happens on the CPU and batch_tfms on the GPU. My question is, if in case of images, does this increase the amount of different images used for training? For example if I use aug_transforms(max_rotate=180) an image is rotated between 0 and 180 degrees. How can I control the amount of rotations for one image? For example I want every image to be used with 5 different rotations, how can that be achieved? Or do I just repeat paths in my training textfile with random rotation.
I’m learning this myself but seems like batch_tfms function is called once for each batch when the batch of data is loaded by the dataloader.
I believe there’s some random amount of transforms/rotation already built into aug_transforms. So if you want to train on 5 different rotation/augmentation of the image, simply train the model through 5 epochs
Late reply but looks like that’s correct! According to the solution to Q.17 of Lesson 2 (Deployment) of the 2022 course release:
item_tfms are transformations applied to a single data sample x on the CPU. Resize() is a common transform because the mini-batch of input images to a cnn must have the same dimensions. Assuming the images are RGB with 3 channels, then Resize () as item_tfms will make sure the images have the same width and height. batch_tfms are applied to batched data samples (aka individual samples that have been collated into a mini-batch) on the GPU. They are faster and more efficient than item_tfms . A good example of these are the ones provided by aug_transforms() . Inside are several batch-level augmentations that help many models.
slightly related with your question although not entirely, where are the docs for these types of concerns? I’ve found this link vision.transform | fastai that talks about the transforms however it says that this is a deprecated version, and the latest version doesn’t seem to have any docs regarding transform, or have i missed it?
 basically item transforms preps everything to the same size, then we can push everything else to the GPU for batch!
basically item transforms preps everything to the same size, then we can push everything else to the GPU for batch!