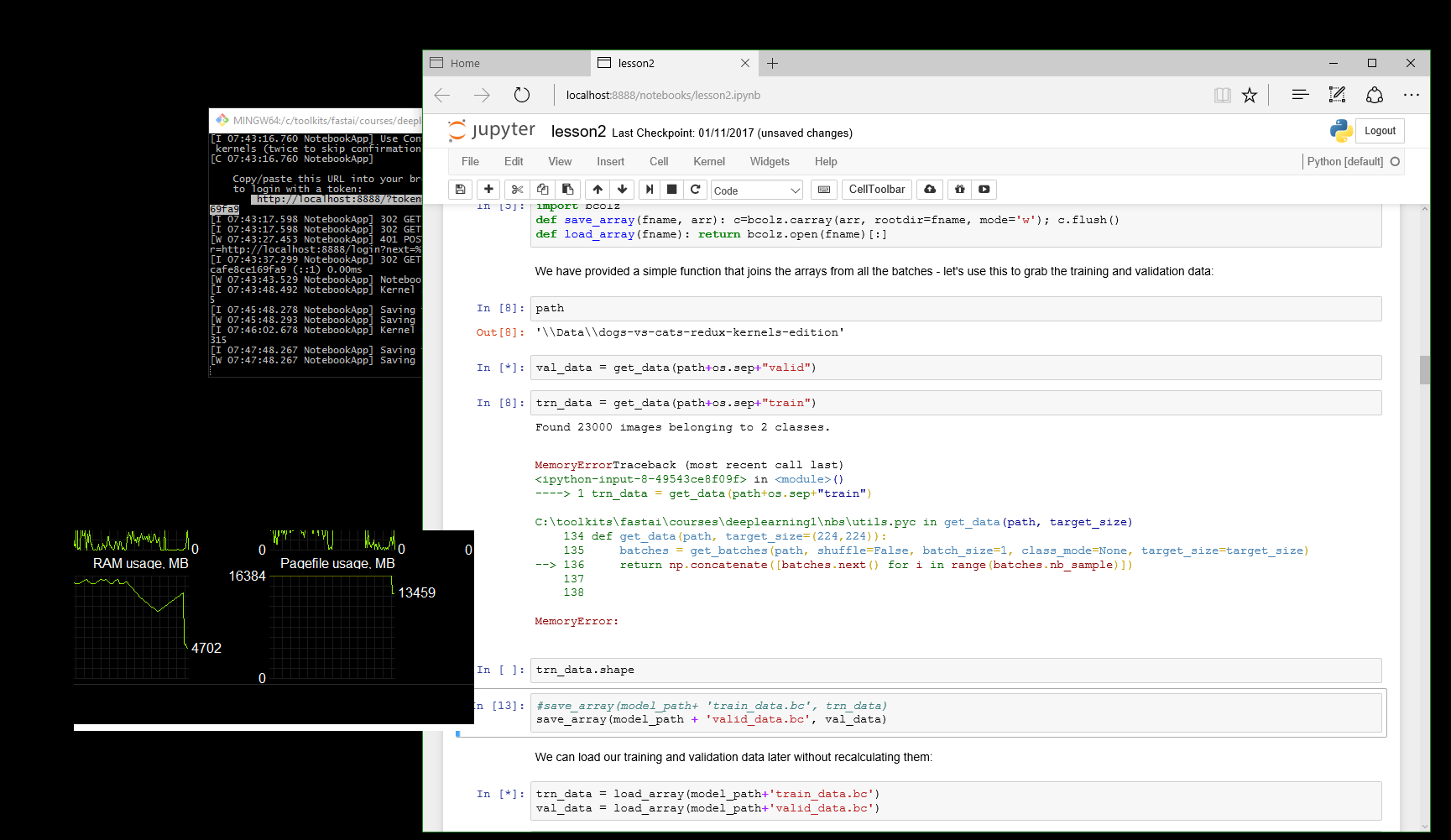
In cell 13, where I call get_data, the memory usage on my P2 instance increases from almost 0 to almost 55GB! The training data on disk is only 550MB (100 times smaller than the memory occupied). After this step, 8/10 times I end up getting OSError: [Errno 12] Cannot allocate memory as you can see in cell 19.
The remaining times when I don’t get the memory error, fit_generator function takes around 600s to run which is the same amount of time it would take to run if I skipped using bcolz. I remember when @jeremy uses load_array to load the preprocessed arrays, and uses fit_generator it takes him only 300s. Why is the universe being unkind to me?
I have tried calling only load_array, to load the preprocessed arrays from disk, but I still don’t see any improvements. Infact using get_data and load_array via bcolz seems to be making things worse by occupying way more memory than it needs too.
What does ‘du -sh data/dogscats/models/train_data.bc’ show for you? For me, it’s 5.5GB.
It could be just that you don’t have enough RAM to load this array into memory - because bcolz uses compression, it seems quite possible the the data is 55GB. Perhaps you could do a back-of-the-envelope calcuation (each float is 32 bits, and you can figure out how many floats are in that array). If this is the case, you’ll need to use batches from disk, or else rather than loading the whole array into memory, use bcolz.open() yourself, which mmap’s the file rather than loading it all.
I’m having an issue with get_data as well, or perhaps more specifically np.concat is eating around 12GB of ram for cats-vs-dogs-redux. I used edge here and closed everything possible, went from 1.9GB usage to ~16GB for 23k files, however, when it crashes you can see that it wasn’t near the maximum. Page file usage is around 30GB. I’m not sure what’s happening here, but I’d like to be able to save my data in stages and append it to the bcolz file to try and fix this issue, is that possible? Is this normal I’m crashing using 16GB of ram? The valid set takes about ~2.5 GB of additional ram for 2k files and does complete successfully, and I am able to save/load it.
TLDR: Is it possible to write get_data in such a way that it uses all of a target batch but saves it in stages.
I was struggling with roughly the same issue and found a hidden comment somewhere on kaggle about an iterator for bcolz Carrays. So now, much like with get_batches, you can use bcolz output with fit_generator etc.
See https://github.com/MPJansen/courses/commit/77acd076e9fd57899617a61af2890c1081622015
If there is interest, I will open a pull request in the course branch.
Usage is like so:
X = bcolz.open(path + 'train_convlayer_features.bc', mode='r')
y = bcolz.open(path + 'train_labels.bc', mode='r')
trn_batches = BcolzArrayIterator(X, y, batch_size=X.chunklen * batch_size, shuffle=True)
model.fit_generator(generator=trn_batches, samples_per_epoch=trn_batches.N, nb_epoch=1)
I’ve got 12gigs of ram and i’m having trouble even saving the files. When I call save_array after generating the training set python just crashes outright. It’s a little frustrating . @glyph How did the extra memory work out for you? I’m thinking of upgrading.
I worked around a similar problem you’ve experienced by splitting up the training set into batches that did fit in memory.
Bcolz arrays support appending, so you could merge the final set together again if you’d like.
Ofcourse having more memory to begin with will help as well, as does increasing your swap area I believe if you are on Ubuntu.
If you find a good way of streaming the predicted output to a file, I would be very interested


 .
.