Previously whenJeremy explained loss function he showed us a y=x**2 graph and explained gradient descent on that graph.
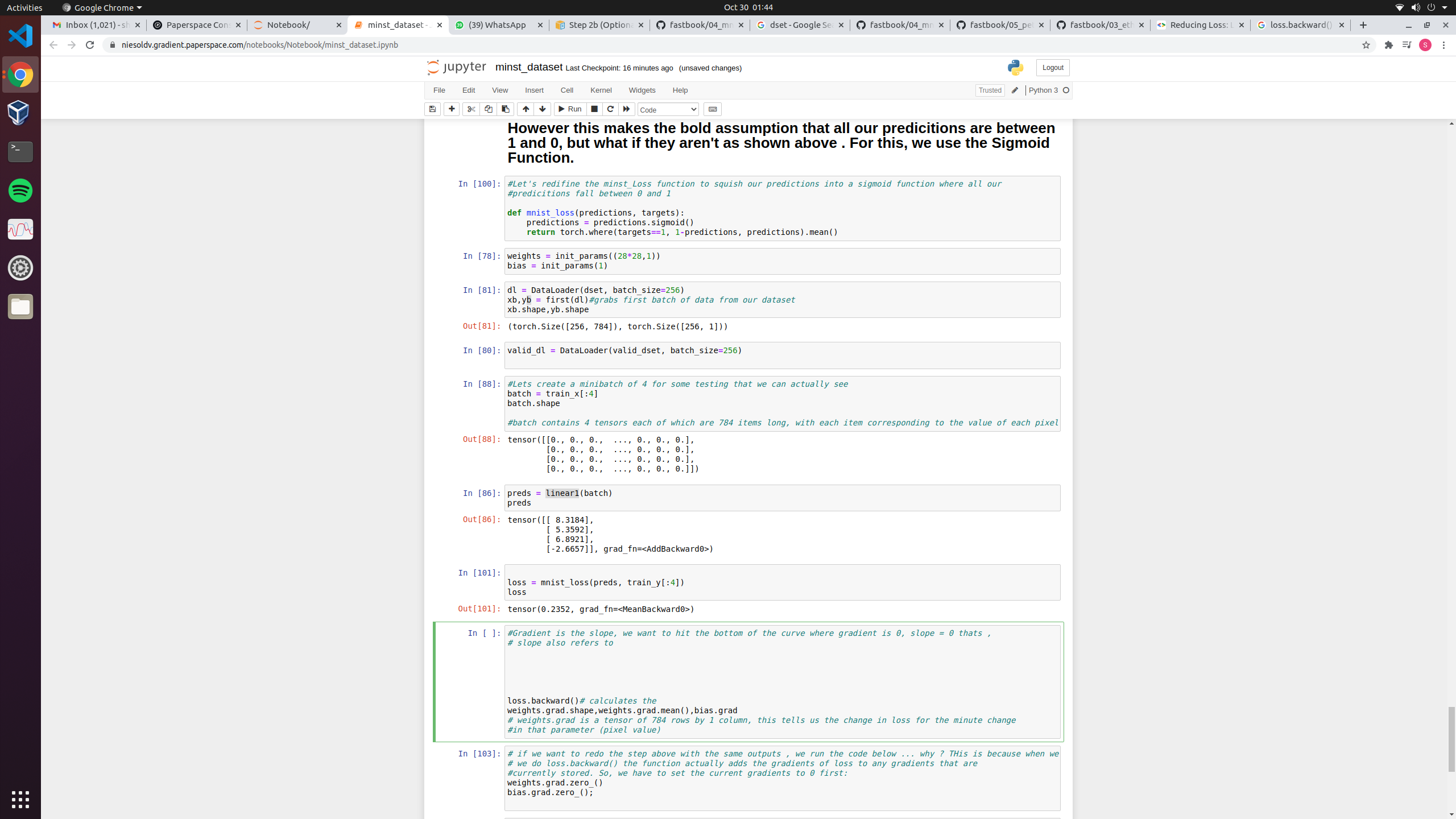
However now I am using a sigmoid function as shown below to get my values
def mnist_loss(predictions, targets):
predictions = predictions.sigmoid()
return torch.where(targets==1, 1-predictions, predictions).mean()
so when i do : loss.backward()
SO from what I understand each of loss for my predictions are being forced to fit onto each of their own y=x**2 graph and each of these would be telling me:
Your prediction’s loss is at point P on a y = x**2 graph. weights.grad tells you how much the loss changes if we change each of your parameters(weight values for each pixel) by a small amount .
Do help me clarify this.
Also the above makes sense but I cant wrap my head around , If I am using the sigmoid function why am I making each of my prediction’s loss sit on a y=x2 curve and gradient descent is being done on that curve? How come it is always a y=x2 curve
also y = x**2 refers to y = square of x … just incase different people refer to it differently
why does he do p.data -= p.gard.data*self.lr
I get what is being done, he is calculating the step(how much we should change the weight or bias to reduce loss) but earlier when he creates the train_epoch function
he does p.data -= p.gard*self.lr , not including the .data this time … he did explicitely state that we do not want the gradient of the step to be calculated and I understand that so shouldn’t we do p.grad.data too ?
Hi Shay,
I believe the first question is about what does the gradient represent. The gradient contains the partial derivative of the dependant variable y with the independent variable, here x, but can generalise (weight1, weight2, …weightN). Consequently, what you get in weight.grad are the N derivatives of y with regard to each weight independently.
Regarding when Jeremy is talking about “how much the loss changes”, let me use an example : if y = 5x, the derivate w.r.t x is y’=5. So you can quantify, the impact of a variation of x for y. In that case, an increase of 1 for x will result in an increase of 5 for y.
For the second question, you use a sigmoid to make sure your predictions are between 0 and 1, that is all. The y=x2 curve is used only to illustrate what a gradient is. PyTorch computes automatically the gradients of your loss function.
Dear Charles you have commented on my second question in the past 2 days, Thank you very much for your explanation. Being new to this i found certain things q hard to pick up initially but your explanations have helped, I also asked another question " Jeremy creates the BaicOptim Class :" in this same string, it should be the reply over yours. If you could clarify that, it’d be perfect.
Thank you very much for your help sir
Hi Shay, yes I had seen it, I just needed more time to investigate. I have run the code with both p.grad.data and only p.grad and it works in both cases. In general, we assign to the p.data field to prevent from computing the gradient but in that case it can be used interchangeably because it is on the right side of the assignment. However, it is important to use p.data on the left side.