Background:
I am supporting a client on a project which was building a deep neural network model to do binary classification problem, relatively small sample size, there are 2 sample groups, one group is around 300+ sample, another is around 100. Each sample is about 20,000 features.
First using train test split, using 20% data for test, never using on training.
Second, using training data perform k-fold cross-validation to train the model.
Third, using the test set to evaluate candidate models.
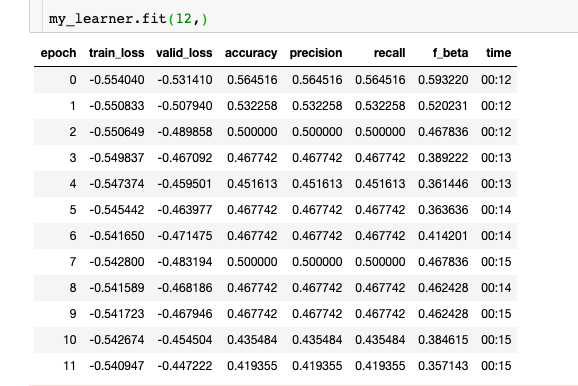
Symptom:
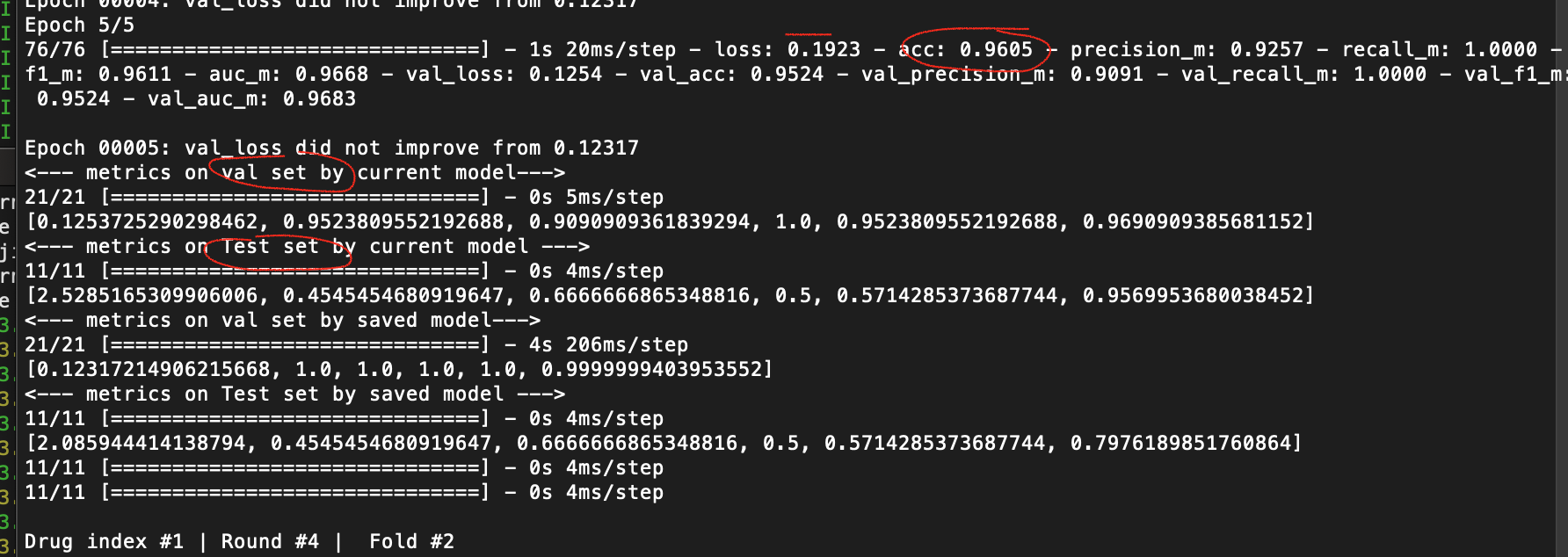
The metrics (acc, precision, recall ) for test set not improved when they performed well on the train and validation set.
The list things I have tried:
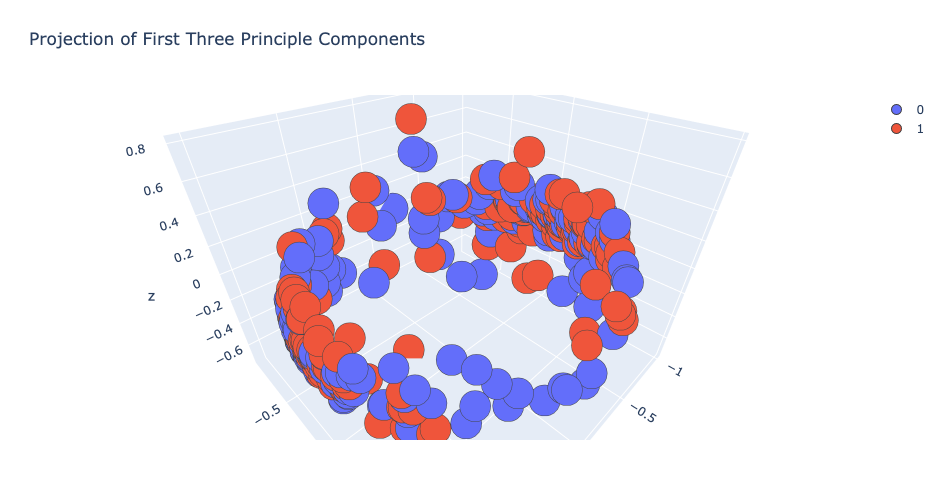
Reduced feature dimensions via PCA with 5, 25, 100 features separately, each time need a much larger model (up to 5 layers, 4096 -> 2048 -> 512 -> 128 -> 64) to perform well on train and validation set, but not on the test set.
Applying dropout with various combination, the batch norm with or without dropout
Tried “Versatile Nonlinear Feature Selection Algorithm for High-dimensional Data” (https://github.com/riken-aip/pyHSICLasso) to analyze why it is the case
Is it Insufficient data to get a big picture.
Using Hilbert Schmidt Independence Criterion Lasso (HSIC Lasso), which is a black box (nonlinear) feature selection method considering the nonlinear input and output relationship, I found that the important features on 3 of them, total data set, train set, and test set, are different. The total data set and train set are almost same, but there is some difference, one of the big problems is that the difference between train set is test set, is this why test set not perform well using thing learn on the train set.
Considering the very limit option to acquire more data (I cannot find more data), is there any way to improve performance on the test set.