For an experiment I wanted to map all the low count categorical values to ‘UNKNOWN’ or level 0 by default. I looked into the following function codes and it seems like it is not supported. This is to avoid create embedding for categorical values which have low frequency. Low frequency categorical values may not get sufficient updates to get trained accurately. Is this already supported?
Anyway I can do preprocessing of the dataframe categorical values to do this.
def numericalize(df, col, name, max_n_cat):
if not is_numeric_dtype(col) and ( max_n_cat is None or col.nunique()>max_n_cat):
df[name] = col.cat.codes+1
threshold = 10 # Anything that occurs less than this will be removed.
for col in df.columns:
value_counts = df[col].value_counts() # Specific column
to_remove = value_counts[value_counts <= threshold].index
df[col].replace(to_remove, np.nan, inplace=True)
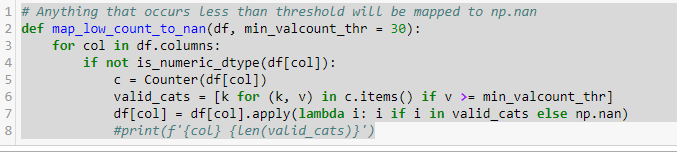
def map_low_count_to_nan(df, min_valcount_thr=30):
for col in df.columns:
if not is_numeric_dtype(df[col]):
c = Counter(df[col])
valid_cats=[k for (k,v) in c.items() if v >= min_valcount_thr]
df[col] = df[col].apply(lambda i: i if i in valid_cats else np.nan)