I have observed, that with the same exact learner setup (1-cycle policy/learning rate of 0.001/default head/5 epochs frozen/15 epochs unfrozen) that the performance of the learner can widely vary if using fastai 1.0.3 or versions above 1.0.3. For instance, in fastai >1.0.3 I get ~65% accuracy on Stanford Cars whereas in 1.0.3 I get over 80%:
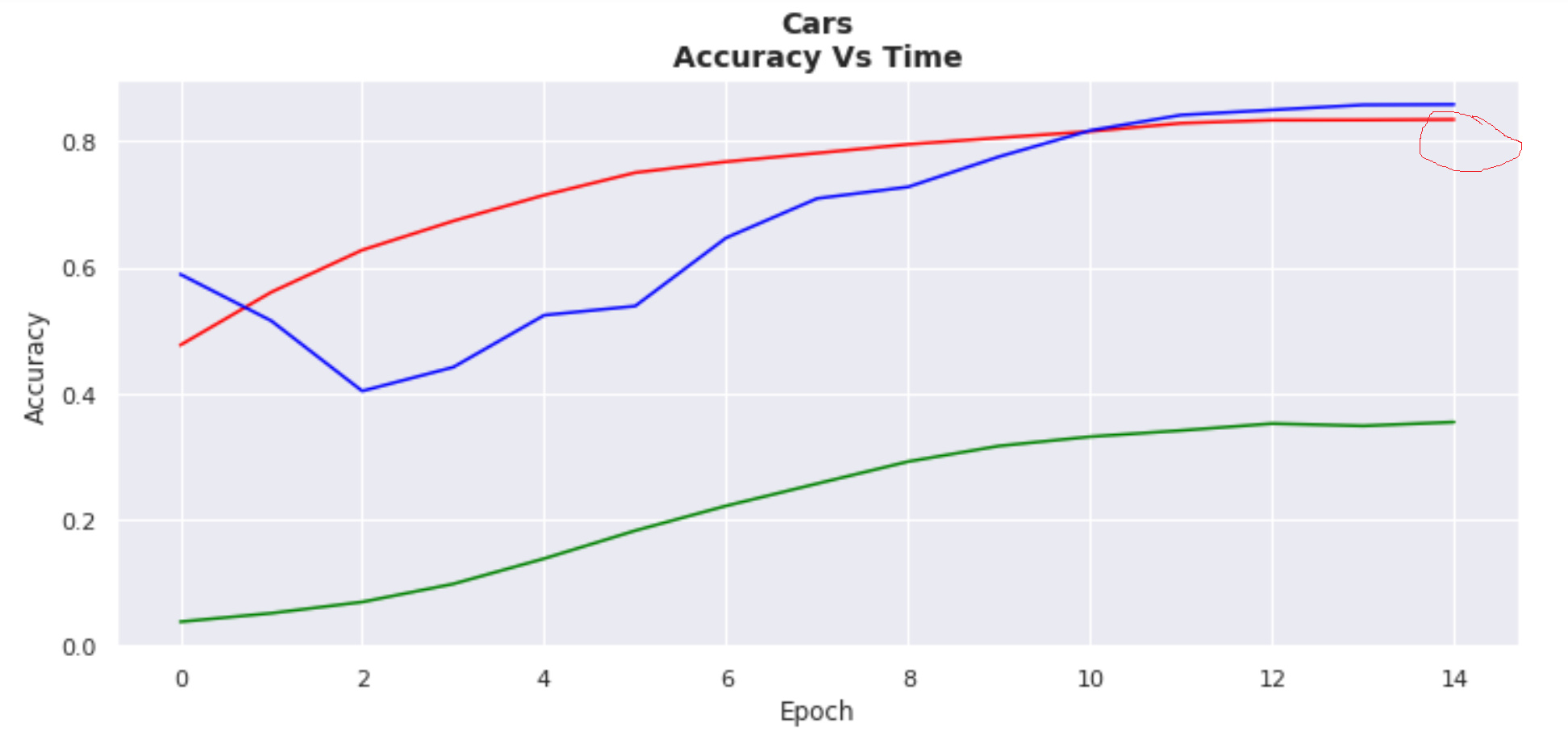
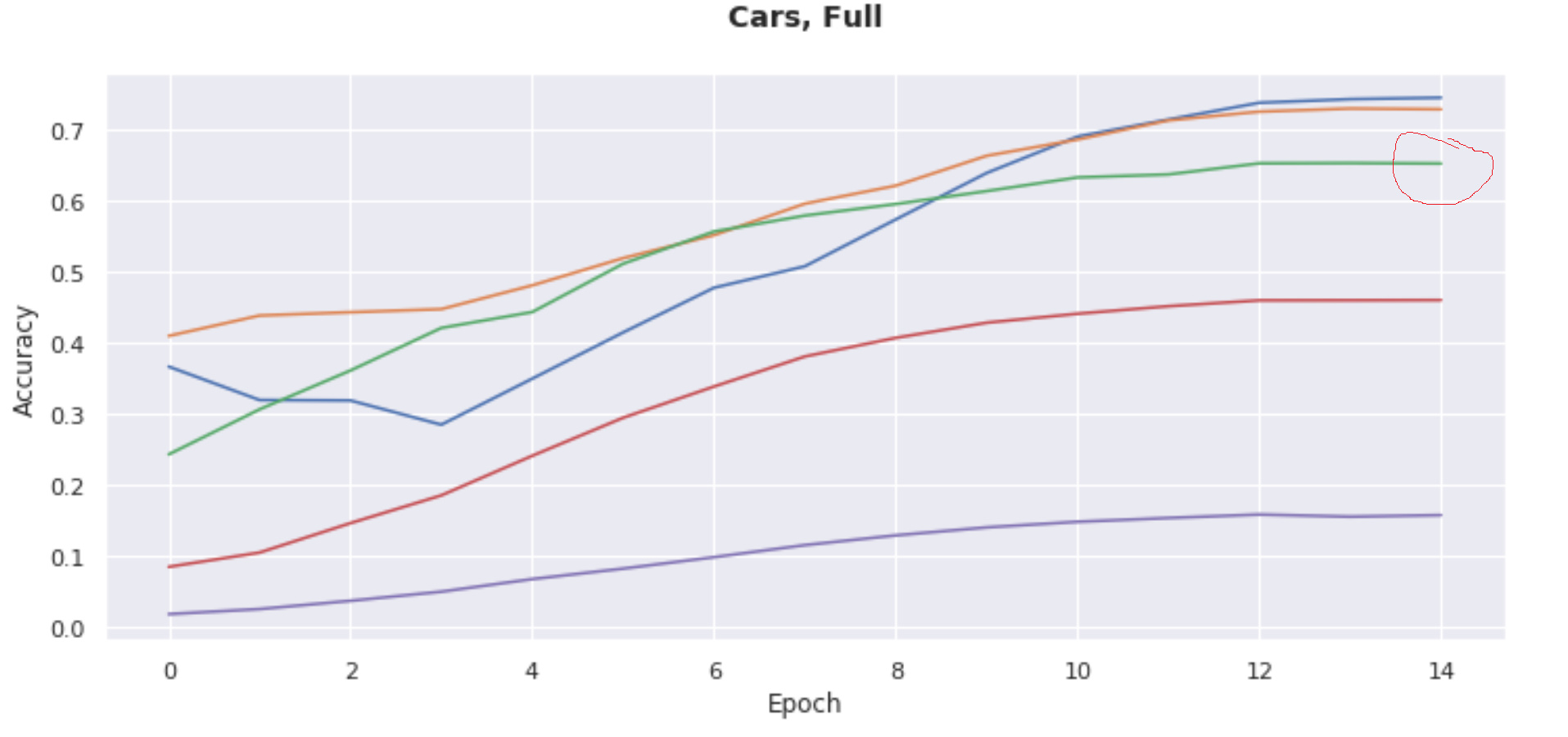
Green line on the test of v 1.0.20 is circled, and red line of v 1.0.3 is circled (the other line plots were separate experiments)
These results I’ve found to be consistent over several trials and can’t be explained by “bad luck.”
What could be causing this discrepancy? Is there some kind of silent gradient clipping automatically added in some versions of fastai but not others? Or maybe there is a different way of calculating the gradients in different versions; for instance silently using fp16 or something that could cause different gradients?