Hey,
Not sure this is the best place to ask but I have been looking at this Netflix presentation and they mention (read slide 15) VBPR as a way to tread cold start for recommender system.
So I read the paper and looked at some code and I can’t help to think that the embedding is really just a Linear layer with bias.
Taking for example this schema:
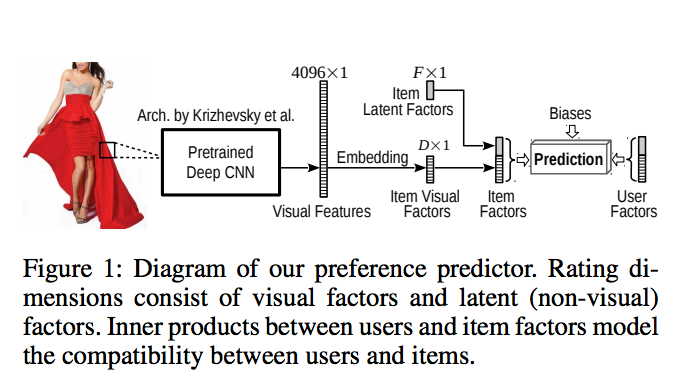
The embedding map the visual features from 4096 to K.
In the tensorflow code linked before it is achieve by doing this:
itemEmb_W = get_variable(type='W', shape=[model.imageFeatureDim, model.k2], mean=0, stddev=0.01, name='itemEmb_W')
itemEmb_b = get_variable(type='b', shape=[model.k2], mean=0, stddev=0.01, name='itemEmb_b')
visual_I_factor_pos = tf.sigmoid(tf.matmul(visual_I_matrix_pos, itemEmb_W) + itemEmb_b)
Where visual_I_matrix_pos is the 4096 vector of information of the image.
Can’t I just use something like torch.nn.Linear(4096,K)?
Please let me know if you need more clarification or if that’s not the right place to post it.