See the results i am getting. Please tell me whats happening internally i just can’t understand whats going on?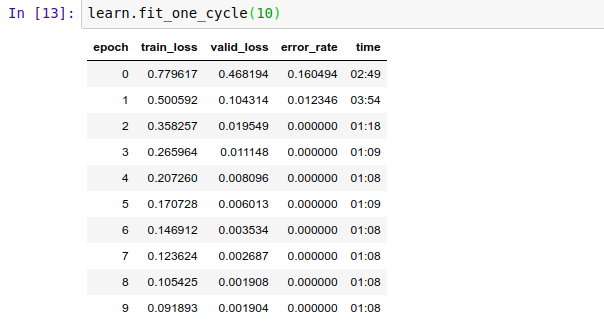
Hmm, I would look for data leakage. Not sure what you’re training but it looks like maybe your validation set has the same content maybe? That’d be my first check at least.
1 Like

This is the batch. These are the images of cracks on walls I have chesked the dataset most of the images looks quite similar although they differ a bit.
i got the dataset friom here - https://data.mendeley.com/datasets/5y9wdsg2zt/2
Can you share the code you are using to create your databunch and learner?
data=ImageDataBunch.from_folder(path,train=’.’,valid_pct=0.2,ds_tfms=get_transforms(),size=224,num_workers=4).normalize(imagenet_stats)
learn=create_cnn(data,models.resnet34,metrics=error_rate)
“The dataset is generated from 458 high-resolution images (4032x3024 pixel) with the method proposed by Zhang et al (2016).”
I am guessing this is the issue you’re running into. Is there a train and test folder? You may need to define your dataset slightly different if they expect you to only use training images for training and test for validation or something.
actually the dataset has 40000 images, i dont have that much computation power so i was trying to create classifiers by randomly choosing 200 images from each category so total 400 images. It didn’t had any seperate train and test folder.
I am unable to understand what had happened train loss is larger than validation loss and also 0 error_rate
right, the dataset has 40000 images, but they are all generated from 458 high-resolution images (assuming I’m reading that correctly).
so what can i understand from this?
Originally, there were 458 images. My guess is that they split this into a training set and validation set then they did whatever method Zhang et al (2016) proposes to generate the 40000 images. So you are taking those 40000 and splitting it into a train and validation set which are going to have some of the 458 in both the train and validation sets.
okay… So what can be the appropriate way to train model in such databases?
Let me download the dataset quick and make sure I’m not completely wrong first.
I would say if this is for learning, I would find a different dataset only because they are generating these from 458 images and they don’t have any validation set set aside. I see a few images that definitely confirm my thoughts on what is happening though. Here are three:



So if one of these was placed in the validation set and the other two were put into the training set, it would be a lot easier for the model to figure out because of the similar features present in these images.
If you really want to see how this model does, you may need to find images of cracked concrete on google images or take some pictures on your own of cracked concrete (and non-cracked) and use those. Probably will need to put your own data together though to really validate that your model is improving.
2 Likes
Oh now I got it. Thanks for the help.