Hi all, just started taking the fast.ai course after circling around/dipping my toes in the subject for a while. I work with cultural heritage and have access to hundreds of thousands of historical and contemporary images and their–so far manually acquired–semantic metadata, so am really excited to feed all this to my models
One issue we constantly have to deal with is cropping images, whether they are documents captured with color and metric scales by their side (example below), projector slides captured together in a single transparent sleeve, or 19th century albums that include a large frame around the image. I have worked with (poorly self-taught) image processing techniques this far and got to a decent result in some cases, but it is always a fine tuning nightmare since thresholding and morphological operation parameters work for one image and then not for the next one. I’ve been thinking of annotating my images and training a model to detect bounding boxes, for instance, but am aware that this would be more computationally expensive than image operations.
Do you think this is a valid – and reasonable – way forward or given the homogeneity of the image structure I should invest in more ‘pure’ image processing? Of course I’m still interested in DL for classifying and indexing images and whatnot, just curious about this particular case.
Thanks for your time (long post I know) and responses!
Document detection is certainly a valid application for deep learning. If you need a place to get started, I came across this tutorial using PyTorch to extract information from images of student-id cards (link). It uses a Mask R-CNN model for detection and segmentation.
You can also train a Mask R-CNN model using the IceVision library (link), which uses the fastai training loop. I have worked with IceVision before for an object detection project, so let me know if you need help installing it.
Here are a few different tools for annotating a dataset.
If you are concerned about speed/efficiency, there are options for optimized inference, like OpenVINO and ONNX Runtime. I’ve worked with both if you need help with those.
thank you so much @cjmills! I’ll take a look at these libraries and get back should I have any questions
edit: and here they come! How many annotated images do you think is a reasonable starting point for this project? As I said, the background is pretty consistent, what changes is the document shape, and slightly position and rotation. Also, do you recommend working with any annotation format? I see there are many (COCO, CVATs, etc) and they come in different formats (XML, JSON)…
I would start with a handful of images to verify your training code works as intended. After that, I would incrementally increase the number of annotated samples until the model performs well enough to meet your needs. Don’t go overboard at the beginning. The pedestrian detection and segmentation dataset in the IceVision tutorial contains 170 annotated images (link) for reference.
IceVision includes parsers for COCO and Pascal VOC dataset formats out-of-the-box (link), so going with one of those would save you the extra work of making a custom parser (link). Double-check that the annotation tool you go with supports the formats you want for the applications (e.g., bounding boxes and masks).
I believe the dataset used in IceVision’s Mask R-CNN tutorial works with Pascal format, but they also include a custom parser for that dataset (link).
Having a bit of a hard time with Icevision, not sure whose fault it is… First I had to play around with installs since there seems to be a conflict between Colab’s default environment and Icevision’s requirements. What worked for me was
but I don’t think I would be able to use torchtext or torchaudio with this setup based on the console output.
Next issue was determining how to use the parser, this is poorly documented but I understand I have to instantiate a COCOBBoxParser object and pass my image directory and annotation file path.
Then the example seems a bit off since running it as-is gives me a couple unexpected argument errors:
show_samples has no label argument
fastai.learner requires a dls argument which isn’t present (I later found this in the tutorial, not sure why it differs from the “example”)
Finally, learn.fine_tune() fails with an AttributeError: Composite has no attribute masks. I can skip to show_results but they are obviously off since I couldn’t fine tune the model. @cjmills is any of this something you have experience with?
Hey @martimpassos, the cumulative dependencies for IceVision can make the setup process a bit convoluted, especially in Colab or Kaggle Notebooks.
If you are going with a pure object detection model (i.e., not Mask R-CNN), you can follow the Colab notebook from my IceVision YOLOX tutorial. The YOLOX model worked quite well for my use case.
If you are using the Mask R-CNN model, I uploaded a notebook that adapts IceVision’s Mask R-CNN tutorial for Google Colab (link). The Install Dependencies cell takes a bit to finish. Note there are multiple backbones for Mask R-CNN. I just went with resnet50_fpn for the notebook.
I can try tweaking the Mask R-CNN notebook for a COCO format dataset when I have a bit more time if you need further assistance.
Hi @cjmills thanks for your continued dedication. I guess I’m still lacking some basic concepts and trying to bite off more than I can currently chew.
The error I get with IceVision’s tutorial relates to the absence of attribute masks. Indeed, I only drew bounding boxes when annotating my images in CVAT. Based on Mask R-CNN name, I’m supposing masks are a required input for this kind of model. Can I achieve this with CVAT?
As you picked up, segmentation is not something I really need, since I’m detecting rectangular shapes, but I like the possibility of detecting slight rotations so I could straighten the document before cropping it. I guess I could achieve that with scikit-image after I get the document bbox though.
Going by the CVAT GitHub project page, it does not appear that the tool supports masking for COCO format, only bounding boxes and points. It does list support for bounding boxes and segmentation masks for the PASCAL VOC format.
Going through the process with a test image, you export the bounding box annotations using the PASCAL VOC 1.1 option and the segmentation mask images using the Segmentation mask 1.1 option. You should be able to combine them into a single folder based on the layout of the VOC dataset used by IceVision.
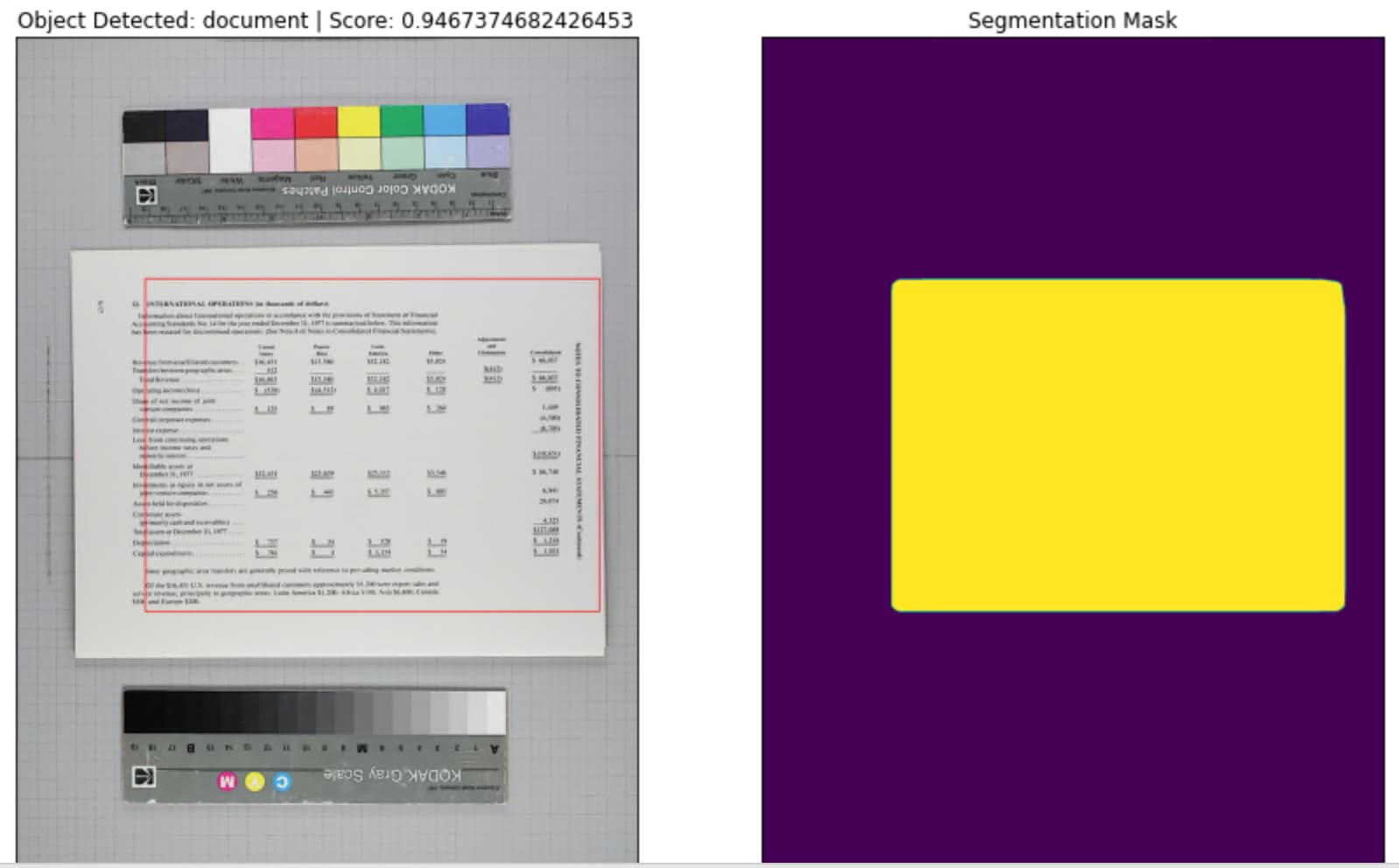
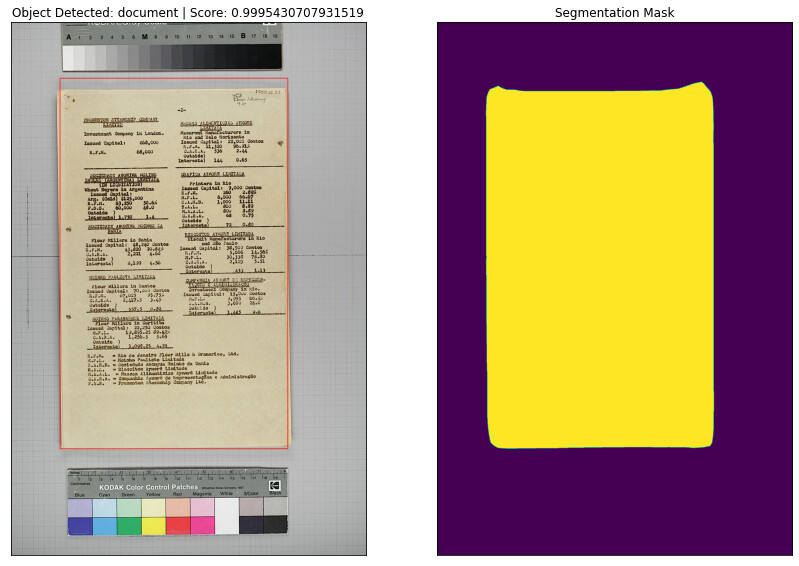
I insisted on IceVision but kept hitting problems with the documentation/outdated versions, etc, and it doesn’t seem to be maintained very often. Also, I figured it would be best to learn a standard library like Pytorch going forward, so turned instead to the Student ID tutorial you shared. This is my initial result:
I used only 50 images to start with. I suppose using more images will improve the detection, but am curious about the difference that more epochs would cause as well.
As for annotating guidelines, I inspected the Student ID dataset and the polygon seems to be drawn exactly on the card edge, which I followed. However, isn’t important for the model to know the object is delimited by such an edge? Will drawing the line ‘too close’ affect the accuracy, should I give the annotation some room around the object?
Since you are following the Student ID tutorial, did you also switch to its annotation format for your dataset (i.e., a polygon with resolution-specific coordinates)? Do the annotations look as intended in the Visualize detection dataset section of the tutorial with your dataset?
The initial sample you shared seems like a good start for 50 training samples. I’m guessing you trained for 20 epochs, like in the tutorial? See if you can make the model overfit with your training data (as long as it’s not too time-consuming). I think the model should be able to memorize that number of samples.
What input resolutions are you using during training and testing?
Regarding where to draw the polygon (following the tutorial’s annotation format), I would keep the shape as tight to the target object as possible unless you wanted the document borders included for some reason.
My images are in the 2500x2000px ballpark, and if I understand the tutorial’s code it doesn’t perform any operation besides converting them to tensors. My total dataset was 50 images, so 40 for training and 10 for validation. I didn’t specify a test set, all I did was box_tensor = detection_predictions[0]['boxes'][idx], etc for each prediction output on a new image.
Regarding the borders, I can always enlarge the bbox a few pixels before cropping, so I guess I’ll keep the annotations tight.
I confess I haven’t given the resolution much thought in this first approach to the issue, as it doesn’t take very long to train 50 samples. I can of course resize them, but accuracy-wise this wouldn’t make much difference, would it? If anything it could bring it down a bit?
I’m also curious: does the model learn by looking at what’s inside the annotations or around as well? In my case, does it learn that a document is only a somewhat homogeneously colored area with black blobs or that it is also a rectangular area surrounded by a checkered pattern and with a ruler and colorchecker around it?
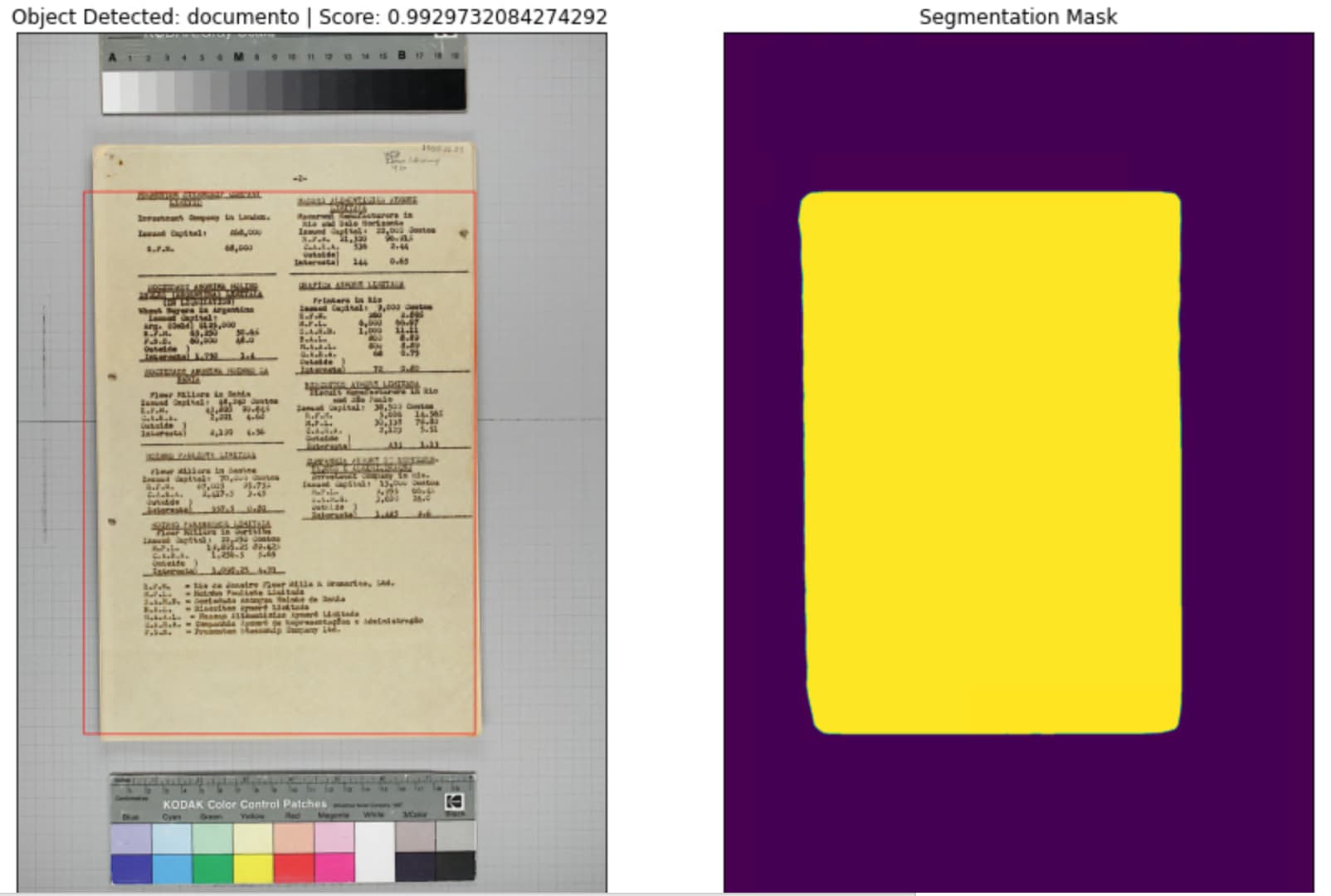
Almost! I annotated 50 more images, tried to get different sheet shapes and colors in the mix. Curiously, I forgot to upload the new images to the folder my notebook is looking at, so this improvement is due to 10 more epochs only as I understand it. I couldn’t locate the one I posted above for a more accurate comparison, but overall the results look better. Here’s another one:
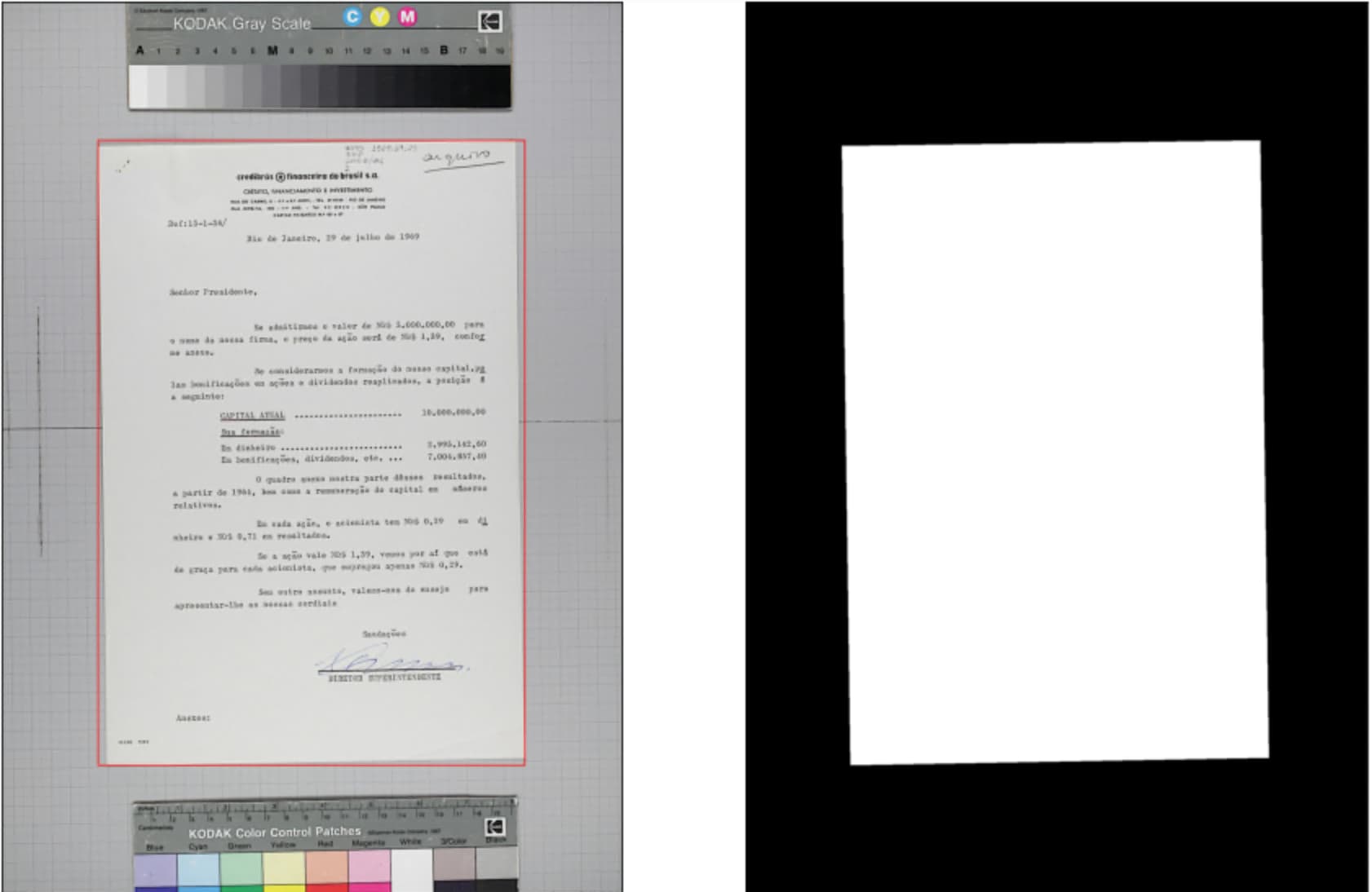
Regarding your previous question, the model looks at the entire image, so it will see the checkered pattern, document border, and rulers when learning to detect documents. It’s trying to guess the annotation values for a given image rather than using them as input information. The white and black visualization is purely for us humans’ benefit.
I’ll annotate maybe 100 more and feel like this will be quite good. It’s still missing smaller documents, will try getting some samples for that. Thanks for all your help @cjmills!