I think he get the notebook of fastai audio (which has the highest score) that now you can find in the github repo and change the sample time to 150ms
You can find alle the code in the repo . What I changed was the crop_size (to 150 ms) and the hop length (to 64):
cfg_voice = AudioConfig.Voice(sample_rate=24414,n_fft=1024, hop_length=64,f_max=12207)
crop_150ms = CropSignal(150)
I also changed the batch-size to 128 (images are small enough).
2 Likes
Thanks @adpostma.
I did see the code in the repo and some of the parameters are clear here (n_fft, hop_length etc.). However it isn’t clear to me what exactly AudioConfig.Voice does. I am guessing it uses librosa in the background but it’s not clear to me what commands they use e.g. do they use .mfcc, .amplitude_to_db, .power_to_db etc.?
In other words, if I wanted to generate that image via librosa alone, I wouldn’t know how to do it. It’s a bit of a mystery to me and I think this preprocessing really makes the difference.
Take a look to this repo for your information: https://github.com/rbracco/fastai2_audio . For detail , I copy the Voice config so you get.
Voice(sample_rate=24414, n_fft=1024, win_length=None, hop_length=140, f_min=50.0, f_max=12207, pad=0, n_mels=128, window_fn=<built-in method hann_window of type object at 0x7ffaedd2e1e0>, wkwargs=None, mel=‘True’, to_db=‘False’)
So they use mel-frequency.
I’m trying to replicate the result with minimum of code but not finish yet 
2 Likes
Thanks @dhoa. I will have to look around there to find out what exactly they do to get those spectrograms. It does look like they use torchaudio to make them and not librosa like I assumed.
Good luck! I look forward to hearing of your success soon 
2 Likes
Hi all. I hesitate to bring this up again. Especially because I am working on ROCKET and not participating in the leaderboard. But I am seeing that my own accuracy std using different validation sets is around .3%. Because the highest accuracies are within this range and we might be tuning to the fixed validation set, it could be prudent to to look at k-fold cross-validation of the methods.
Has anyone already tried a different train/validation split?
1 Like
I’ve tried some combinations of mfcc / spectrogram with .power_to_db / .amplitude_to_db and a bit of parameter changing (e.g. n_mels) with librosa but can’t seem to quite get that kind of spectrogram. Quite a mystery!
I think if we get the same level of pre-processing as the “fastai 2 audio” library, we can really see the effect of different architectures / approaches.
1 Like
It is because of the default parameters of librosa and pytorch are differents. I tested with the same set of parameters for both ((sample_rate=rate,n_fft=1024, hop_length=140, n_mels=64)) and get the spectrogram of librosa too much dark compared to the other.
Then I tried to change the power param in librosa and it seems to have better spectrogram, not sure if I do it right but it seems to be a reasonable choice.
spec = librosa.feature.melspectrogram(x, sr=rate, n_fft=1024, hop_length=140, power=0.76)
2 Likes
Cool, thanks @dhoa! I didn’t think of changing the power parameter to a fractional value! Did you check if it improved your accuracy?
1 Like
A little bit. Not as good as I expected. I will try xresnet to see
2 Likes
Hey @Pomo, I agree with your concern, although I must confess that I haven’t tried different splits yet.
I am currently focusing on the overall workflow / method since the spectrograms have plenty of parameters to play around with. That’s probably an advantage of ROCKET over the spectrogram method? (Esp. if one, like in my case, doesn’t completely understand the effect of spectrogram parameters  ).
).
Thanks for the info on your experiments! Really appreciate it.
PS: I think you mean that your error rate is 0.3% and not your accuracy, right?
1 Like
@radek if I understood your post and the dataset correctly, there is only one macaque call in the dataset - “coo” calls? Do you know if there are datasets with all the different calls of macaques available?
Yes, you are right I am not aware of any dataset that would contain the other calls, but wouldn’t hurt to look, maybe someone else can find an interesting dataset we could work on
I am also looking at a new dataset for us, one where we could try different techniques and that could offer a different type of challenge. Likely it will be birds this time, but don’t have anything ready yet
1 Like
Hi Gautam. Thanks for responding. ROCKET’s accuracy is typically around 97%. The standard deviation of the accuracy across different validation splits is about .3% (4 samples). If that variation also applies to the spectrogram methods, a method we think is better may not actually be better over different train/validation splits.
I don’t know if it’s an issue, but it seems worth checking.
1 Like
Hi all. I am posting my git confusions here on the chance it will help others.
What I have done so far…
- git clone of the open_collaboration repository to my local drive.
- make a branch called ROCKETSound.
- add my contribution as folder ROCKET_Sound
- commit the branch.
I don’t understand what to do next to make a PR. Push (in GUI SmartGit) says…
~/fastaiActive/open_collaboration_on_audio_classification> git -c credential.helper=/usr/share/smartgit/lib/credentials.sh push --porcelain --progress --recurse-submodules=check origin refs/heads/ROCKETSound:refs/heads/ROCKETSound remote: Permission to earthspecies/open_collaboration_on_audio_classification.git denied to PomoML. unable to access 'https://github.com/earthspecies/open_collaboration_on_audio_classification.git/': The requested URL returned error: 403
So I am guessing that we need permission to add a branch to Radek’s repository???
I also hit “Fork” in the Github browser, which seemed to copy the original Github repo into my own Github account.
What’s next, please?
1 Like
Ok, now I understand that you fork the repo to your own account and change it there. After repeating the above steps and a Push, I have two Github branches, Master and RocketSound.
The “New Pull Request” button on the original Github page led to a labyrinth of obtuse choices and errors. Thus this second post. But after waiting a few minutes, the original page showed a button offering to make a PR from my fork, with everything already filled in.
So I think all is well. But there’s probably a better “right way”.
2 Likes
Thank you for the PR @Pomo! Super awesome for us to have this method in the repository.
The workflow for opening a PR is as you described. It is best to:
- On github, navigate to https://github.com/earthspecies/open_collaboration_on_audio_classification and press the fork button (this makes a copy of the repository under your github account)
- Go to the repository under your account (this one you will have write access to), https://github.com/PomoML/open_collaboration_on_audio_classification in this case.
- Clone the repository to your machine.
- Make any changes that are needed and then:
git checkout -b <branch name>
git add .
git commit -m '<name of your commit>
git push origin <branch name>
5.Go to the repository on github under your account and hit the create PR button that should now be showing.
Not the most intuitive chain of what needs to be done to say the least
BTW I did this from memory so if someone else tries this and it doesn’t work, maybe I missed something, please let me know
Also, @pomo left a comment in the repo, that there is some fastai v1 code at the bottom of this notebook that could use porting to fastai v2. If anyone is looking for a challenge, consider giving this a shot 
Thank you again @Pomo for this superb contribution!!!
2 Likes
I am able to replicate the result of fastai audio. The key here is just using the torch audio to create the Mel Spectrogramme rather than librosa, I haven’t digged into details of these 2 library to see why. With xresnet after 8 epochs, I got error rate 0.002745 which is the same as fastai audio.
I have just created a PR if you find it interesting Radek
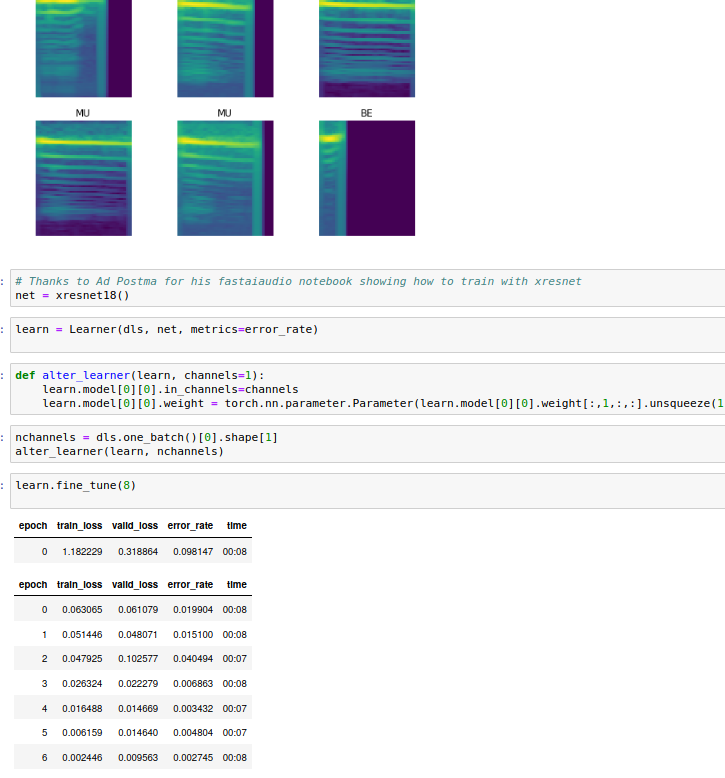
4 Likes
@dhoa, thanks for the result! This is quite mind-boggling. It means that just using spectrograms from torchaudio instead of librosa result in a 10x reduction in error?! Very intriguing 
I would be happy to get your code
1 Like
Amazing work happening in this thread  Enormous thank you to everyone sharing their work on github and their expertise in the comments of this thread.
Enormous thank you to everyone sharing their work on github and their expertise in the comments of this thread.
We are now officially at four different models 
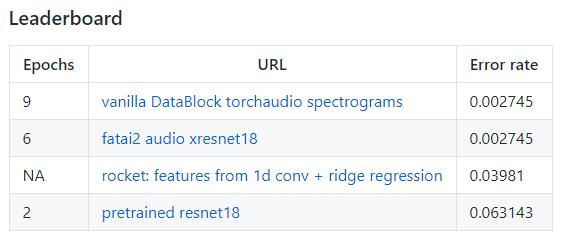
6 Likes