I’m putting together a notebook that hopefully explains Convolutional Layer with a Twist for everyone. For those who have never heard about it, I recently used it on ResNet for the Imagenette/Imagewoof challenge, and it appears to be working pretty well (with some surprises). As it can replace any 3x3 convolutional layer in your model, I’d very much like to see it applied to other kinds of CNN models (detection, GANs, etc.) and datasets.
I’m trying to use fastai’s fastpages to “publish” it, and it’s still a draft. For one thing, I couldn’t find instruction for writing LaTeX which it promised to support. [Update: I was dumb… simply using $ signs in markdown works.] (Jupyter notebook, LaTeX, and a public comment section is a killer combination, from my view.)
I’d also like to ask for suggestion of a notebook that has code that takes an image, turns it to a PyTorch tensor, passes through a neural net, and “plots” the outcome (or a feature map) as an image. That would help me a lot. Thanks in advance!
Looks like it’s showing what part of the original image is “activated” at a certain feature map, while what I’m looking for is just showing the feature map, of a model that is simply one Conv layer (not a model at all). I’ll take a look.
It’s too big a hammer because I’m new to fastai. Nothing against it.
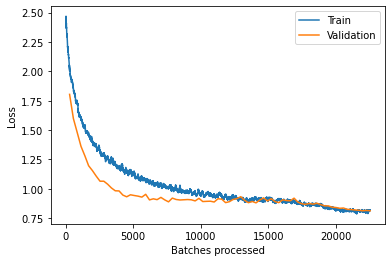
I’d like to point out one problem that seems to happen a lot, if not always, and that is the training loss can stay well above validation loss. When I asked this, people say my training is not done right. But I don’t know what to do about that.
Here’s one run, size=128, epochs=80, lr=4e-3, mixup=0.5
I guess my question would be, for those who have done lots of training (from scratch), how often do you see train_loss > valid_loss? Is that a bad sign and how do you “fix” it?
Where is your setup different from the standard setup? (This should be the best hint on where to start looking.)
Are there differences between the train and valid phase? (E.g., with MixUp you can see a similar change in the loss, if MixUp is only active during training, which should be the case.)
Did you do a lot of hyper parameter tuning and maybe overfit to your validation set?
How big is your validation set?
What happens when you use another train/valid split?
You are using very high mixup number. So you augment hard. If you compare training with augmentation vs wo it will be usually same picture. If you training loss still higher then validation it mean you can train longer. Or, if you want higher result on this, reduce mixup.
Is it imagenette of woof?
Thank you both for the feedback. I used @a_yasyrev’s last notebook and run for 80 epochs. I’ll try it with a lower mixup.
It’s Imagewoof2, so I thought that already had a fixed train/valid split.
Am I correct that mixup does not do “rotation” of the images? I think I tried to manually add rotation in transforms (no mixup), but didn’t see much improvement.
I did a 200-epoch run, but the result is no better than the 80-epoch runs above. I also wanted to see what the centers are at the end of training.
[Update: that was with mixup=0.2. I then did a 200-epoch run with mixup=0.5 and reached 88.65 or 88.83 (but without ConvTwist it also reached 88.57 and 88.80, compared to 87.20 on the leaderboard). But I just found out that the stem part of ResNet50 didn’t use ConvTwist.]
Well, I’ve been making a lot of changes, but haven’t seen definitive improvements…
(Only been testing on Woof2, size=128epochs=80)
First, for each of the additional conv operations that I said cost 4 parameters per filter, I can reduce it to 2 parameter without seeing much difference. And for long runs, it seems that I can do away with the “centers”. I also added an iters parameters, that runs the same ConvTwist layer multiple times. Then I also played with the groups parameter in Conv2d (aka cardinality in ResNeXt), that reduces the overall model size without sacrificing performance (Maybe because ResNet50 was designed for ImageNet, and for a 10-class dataset a much smaller network can work just as well. If that hypothesis is true, one could randomly “freeze” half of the connections at the outset and achieve the same accuracy.)
What I feel could be a possible direction is to tweak the “block pattern”. Not the block one normally means in a neural network, but the block as in “block-diagonal” matrix. With groups=2 the kernel is like a 2x2 block diagonal matrix. What if we make it off-diagonal?
Here’s the new version of ConvTwist
class ConvTwist(nn.Module): # replacing 3x3 Conv2d
def __init__(self, ni, nf, stride=1, groups=2, iters=4):
super(ConvTwist, self).__init__()
self.twist = True
self.same = ni==nf and stride==1
if not (ni%groups==0 and nf%groups==0): groups = 1
elif ni%64==0: groups = ni//32
self.conv = nn.Conv2d(ni, nf, kernel_size=3, stride=stride, padding=1, bias=False, groups=groups)
if self.twist:
std = self.conv.weight.std().item()
self.coeff_Ax = nn.Parameter(torch.empty((nf,ni//groups)).normal_(0, std), requires_grad=True)
self.coeff_Ay = nn.Parameter(torch.empty((nf,ni//groups)).normal_(0, std), requires_grad=True)
self.iters = iters
self.stride = stride
self.groups = groups
def kernel(self, coeff_x, coeff_y):
D_x = torch.Tensor([[-1,0,1],[-2,0,2],[-1,0,1]]).to(coeff_x.device)
D_y = torch.Tensor([[1,2,1],[0,0,0],[-1,-2,-1]]).to(coeff_x.device)
return coeff_x[:,:,None,None] * D_x + coeff_y[:,:,None,None] * D_y
def full_kernel(self, kernel): # permuting the groups
if self.groups==1: return kernel
n = self.groups
a,b,_,_ = kernel.size()
a //= n
KK = torch.zeros((a*n,b*n,3,3)).to(kernel.device)
KK[:a,-b:] = kernel[:a]
for i in range(1,n):
KK[a*i:a*(i+1),b*(i-1):b*i] = kernel[a*i:a*(i+1)]
return KK
def _conv(self, inpt, kernel=None):
permute = True
if kernel is None:
kernel = self.conv.weight
if self.groups==1 or permute==False:
return F.conv2d(inpt, kernel, padding=1, stride=self.stride, groups=self.groups)
else:
return F.conv2d(inpt, self.full_kernel(kernel), padding=1, stride=self.stride, groups=1)
def forward(self, inpt):
out = self._conv(inpt)
if self.twist is False:
return out
_,_,h,w = out.size()
XX = torch.from_numpy(np.indices((1,1,h,w))[3]*2/w-1).type(out.dtype).to(out.device)
YY = torch.from_numpy(np.indices((1,1,h,w))[2]*2/h-1).type(out.dtype).to(out.device)
kernel_x = self.kernel(self.coeff_Ax, self.coeff_Ay)
kernel_y = kernel_x.transpose(2,3).flip(3) # make conv_y a 90 degree rotation of conv_x
out = out + XX * self._conv(inpt, kernel_x) + YY * self._conv(inpt, kernel_y)
if self.same and self.iters>1:
out = inpt + out / self.iters
for _ in range(self.iters-1):
out = out + (self._conv(out) + XX * self._conv(out, kernel_x) + YY * self._conv(out, kernel_y)) / self.iters
out = out - inpt
return out
And here’s the notebook that you can directly play with
As much as I like to see ConvTwist fair better, I’ve been testing the “permuting groups” idea further, which is mostly orthogonal to Twist. Still following the Bottleneck architecture of ResNet50 (but deeper), I split the 3x3 conv into groups of 8 channels each (thus significantly reduces the model size). The permutation that seems to work well consists of “4-cycles”, if you know some basic group theory.
On size=128, epochs=80, it achieves 88.62 with layers=[4,6,8,10].
On size=192, epochs=80, it achieves 89.79 with layers=[4,6,8,10]. How does it seem to you, @a_yasyrev? You have been testing on this setting, right?
On size=192, epochs=5, it scores 80.87 on 5-run average. (The notebook above has been updated to contain the results.)
Edit: I should add that the “permuting the groups” has a nice interpretation in terms of the small-world network of Watts-Strogatz from late '90s. (Here’s a beautiful rewrite of the paper.) The name came from the saying “it’s a small world” when two people first met and found they had a sort of six-degree connection. You don’t need everyone connected to everyone else (too costly), but having small hubs (school friends, coworkers) and occasional connections between them, is sufficient to have the small-world phenomenon. In ResNet, at least for our 10-class toyset, having the fully-connected (on the channel level) may be wasteful.
Unsurprisingly, there are DL papers that have “small world” in the title, but I can’t make the judgement if they are talking about the same thing. (Update: I realized “permuting the groups” is like shuffling the channels, and that reminds me of ShuffleNet.) By the way, where does one find an expert’s “review” on a paper, say a year later, that hopefully gives a fair take whether the idea pans out or not? There are just too much stuff on arXiv.
Its cool!
Tried new version (still in work), on size 192, 5 epochs, layers [3.4.6.3] got 78.2, std 0.009, 5 runs.
On [4,6,8,10] got 796, anyway its very good!
This 64x64 grid represents a 64x64x3x3 kernel, dividing the 64 channels into 16 groups of 4 channels each. The 16 groups are further grouped into 4 “meta-groups”, and the permutation is cyclic within each meta-group.
Next I’d like to add connections between the meta-groups, like this: