In lesson 6, Jeremy mentioned that it should be straightforward to use fastai2 to apply pretrained models to images with more than 3 channels, such as satellite data.
I was wondering who had already experimented with that. I guess one option would be to insert a linear layer just after the input, taking the n channels down to 3. And that layer should also be made trainable during finetuning?
Like you said, a trainable linear combination of n channels to 3, basically a 3xn matrix multiplication of image planes. I imagine nn.Linear can be used for this with the right sequence of transpose, flatten, and reshape.
Replace the first conv2d layer with one that takes n image planes and gives the same output activations. Copy the pretrained weights to 3 planes. The new planes could be initialized randomly or with the mean of the pretrained ones.
BTW, I have never understood whether the pretrained conv2d kernels are similar between planes or completely independent. Does anyone know?
Thanks! Yes good point, your approach (2) seems much better since we start out in a less perturbed state, especially if the new weights are initialized to very small values.
They must be heavily correlated since the images are heavily correlated across channels. But it would be fun to verify this
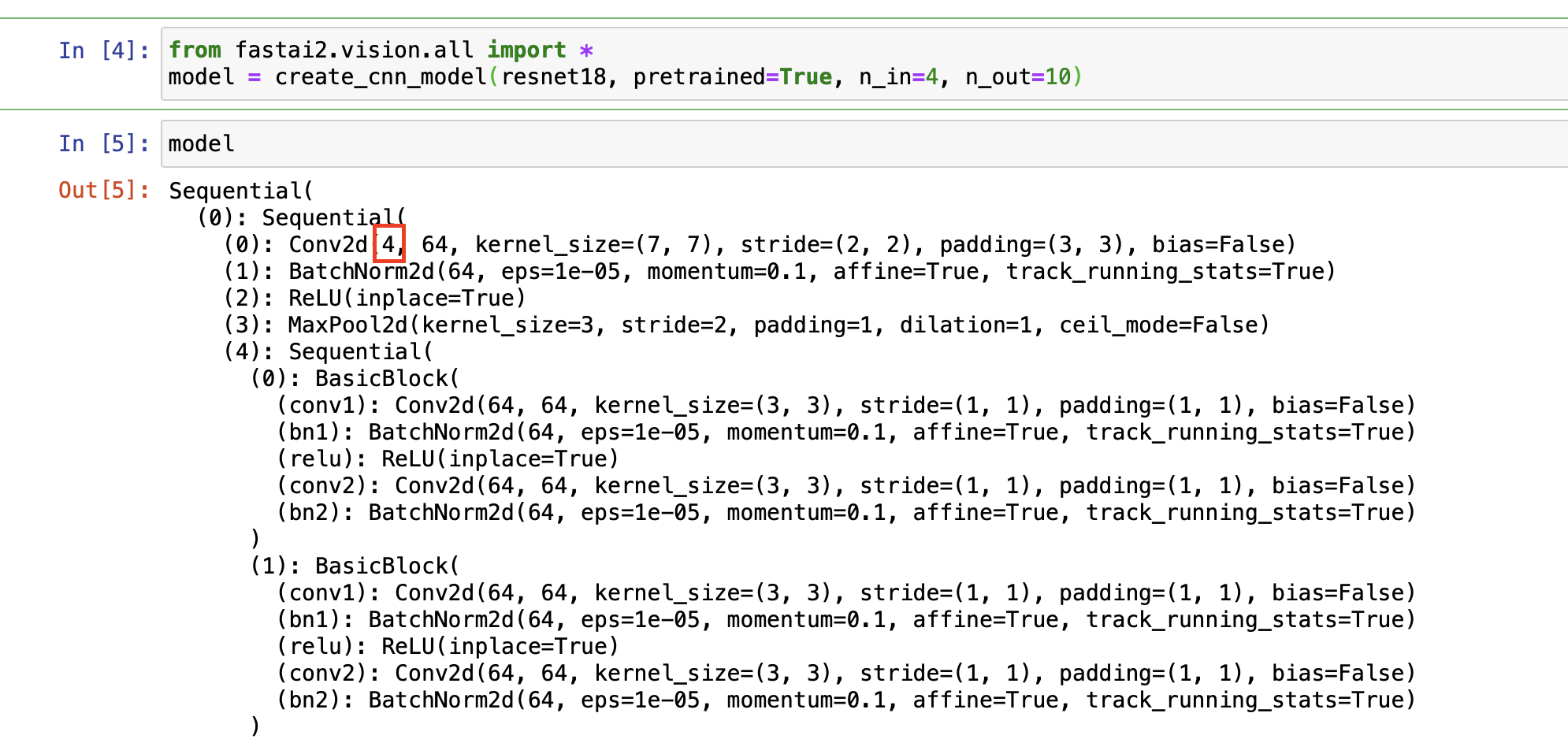
the Learner.create_cnn_model has a parameter n_in - which is used in _update_first_layer (description of the method “Change first layer based on number of input channels”). So that should be worth a try:
n_in should be the number of input dimensions
n_out should be the number of classes in the dataset / outputs
from fastai2.vision.all import *
model = create_cnn_model(resnet18, pretrained=True, n_in=4, n_out=10)
I was thinking of overlaying several satellite images on top of each other, identical positions but from different satellites and at different times, especially from Sentinel-1 and Sentinel-2. So each “image” would really be a stack of images.
when we convolve with a a 3x3 filter, in reality that is a 3x3x3 filter (for a 3 channel image) and we have 27 dot-products(9 for each of the 3 channels) which is summed to give us a single number. So the filters being learnt is for a combination of the channels(image planes).
fastai randomly initializes the extra filters(so when c_in =4, 3 filters are from the pretrained model and the 4th one is randomly initialized, it doesn’t take the average of the other 3 channels)
If the misalignment is always the same it may be fine, otherwise it could be much harder for the model to learn (if there are features that need info from many channels)
On a somewhat related note, I cannot figure out how to apply Image transforms (like Resize or CropPad) to hyperspectral images. I suspect it’s because I’m treating the inputs as tensors rather than (PIL) Images but I am not sure (I am using a custom Image class, and I can verify that dihedral transforms do work). Either way, I can get a learner to train on these images but these image transformations seem to not be working. Has anybody ran into or solved this problem?
(I originally asked the question here but didn’t get any answers.)
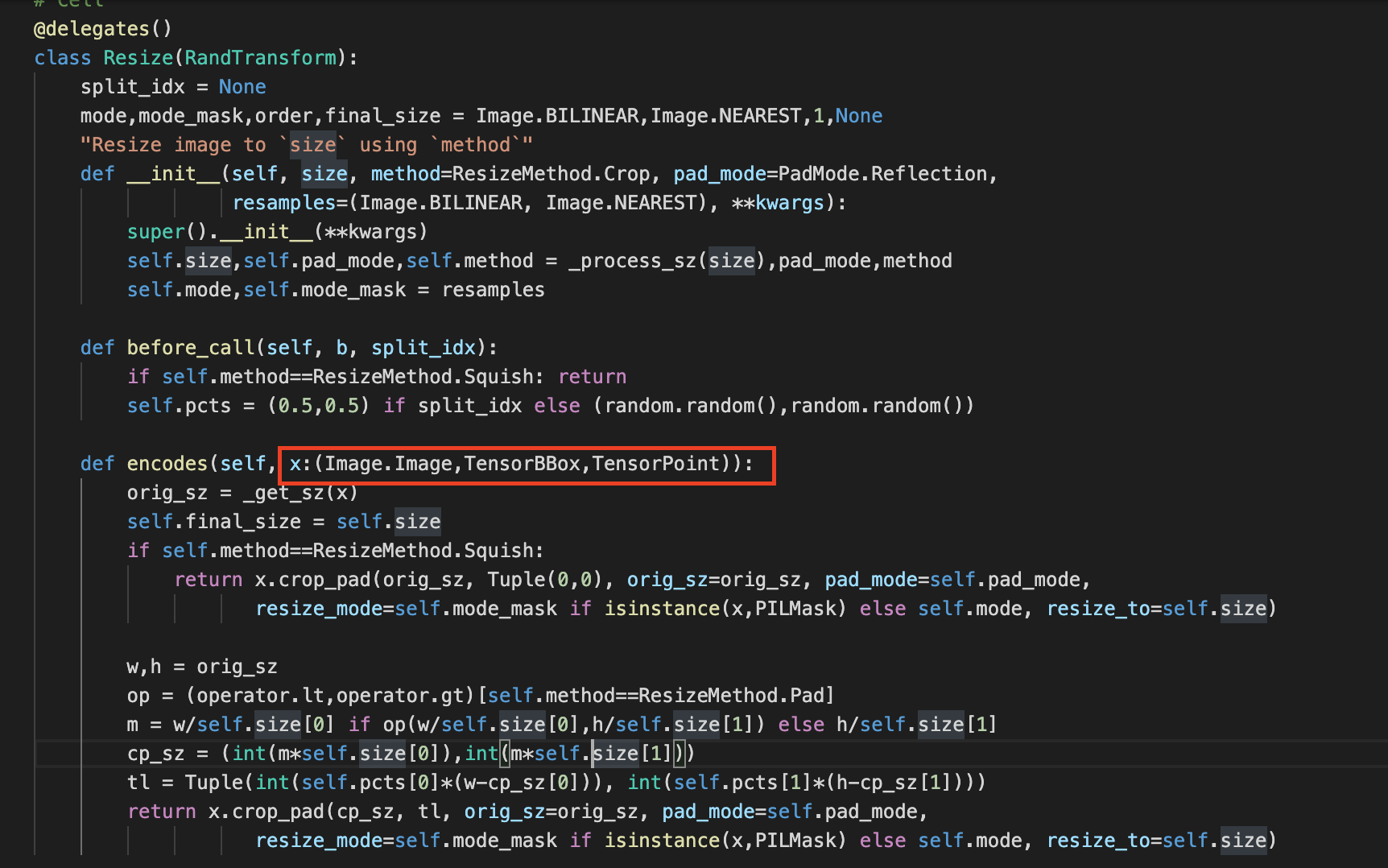
fastais default vision transforms e. g. Resize will only be applied to the following classes: (PIL)Image.Image,TensorBBox,TensorPoint (see the screenshot below). I guess you have to write your own “ImageNdimTensor” class, block and transforms. Maybe there is another way (does PIL support 4 dimensions somehow maybe?!)
I did something similar for a Conv1d CNN - maybe you get the idea:
Awesome, this is super helpful – thanks very much! If I get this straight, it means that I’ll need to write some Transform classes such as
class grizyCropPad(Transform):
[...]
def encodes(self, o: grizyTensorImage):
[...]
class grizyResize(Transform):
[...]
[...more transforms...]
class ToGrizyTensor(Transform):
[...]
def encodes(self, o: grizyTensorImage):
o = tensor(o).float()
return o
And then pass in grizyCropPad to the item_tfms argument while constructing the dataloaders.
yes exactly. as far as I understood Transforms will be applied to both train and valid dataset and RandTransforms only (randomly) to the train dataset. But I am not 100% sure about that
with split_idx you should be able to control which subset the transforms are being appliedto.
if it is None then it is applied to both train and valid
if is 0 then only train
if is 1 then only valid
This seems to work fine to create the model, but I’ve been thinking: wouldn’t it make sense to only unfreeze this layer (full of zeroes) first and train it a bit, before unfreezing the entire model?
I am trying to figure how to unfreeze only the first layer of a resnet (rather than the last), not sure since even when the learner is frozen, I get the following:
 I’m kind of stuck with my current project and looking for something new
I’m kind of stuck with my current project and looking for something new