Hello guys,
I am working on a project of extracting interesting information from receipt (Japanese), like restaurant name, total amount, phone number, date, etc.
It is a kind of OCR problem, is there anyone has tackled similar projects before? I am going to use SSD to detect keyword on the receipt and then crop area around that keyword and send it to standard OCR reading machine like Tesseract. Any comment on the approach, please.
2 Likes
Hey,
I am also working on a similar problem.
Let’s connect,
1 Like
You can probably use OpenCV to process the image, apply perspective transformation which will help you generate a top down view of the receipt. This would help reduce your error rate. YOLO/SSD both works great for detection. detect your keywords with these and then pass it as an input to your tesseract engine
hi @Abhijeet01,
nice to talk with you.
1 Like
Maybe interesting for you:
tesseract might be used for recognition step. My problem to solve is how to firstly detect correctly position of each interesting field on the receipt like name, address, phone number, etc
Would it be an option to get in a first step all the text and then apply NLP to get the information?
I’m not sure which approach is better, but NLP has tools like NER & Co. which are quite optimized for such tasks.
but the ocr returning text for receipt is kind of short, only 2-3 words per sentence. I don’t think NER can recognize which class that block belong to.
ICDAR 2019 is hosting a competition to extract information from receipt
https://rrc.cvc.uab.es/?ch=13&com=evaluation&task=1
1 Like
@phucnsp please check the amazon textract. It is able to extract data very efficiently and accurately.
But so far it is just for english. I am working on japanese dataset
@phucnsp
okay.
Can you do a simple experiment? I guess it will work for Japanese dataset!
- upload your input data(jpg/png/pdf) to google drive.
- open that image using google docs , file with the same name of type google doc will be generated in your google drive. This file will additionally contain extracted information from that input image.
- Make a parser and extract relevant text.
Please let me know if it works.
i tried it, it recognized raw text worse than google vision and the text returned also not in japanese
@phucnsp Please Let me know if you find any solution.
Hi phucnsp,
Do you have any examples of your images? They would be helpful to see before recommending an algorithm to try.
Are you in a constrained or unconstrained environments?
If all text is machine printed, EAST works fine 
Also if your receipts have all the same format you can do some manual preprocessing,
1 Like
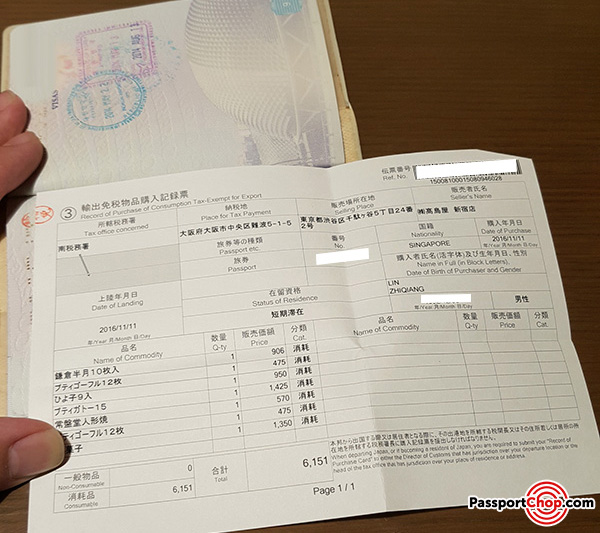
my data is kind of like this, japanese document and need to extract some information from it like name, address, phone number, etc
https://rrc.cvc.uab.es/?ch=13&com=evaluation&task=1
ICDAR 2019 is hosting a competition quite similar. I am trying to implement text detection algorithm by combining EAST + Multi oriented corner, according to some description from H&H Lab, ranking 3 for task 1.
2 Likes
@SiddharthGadekar alerted me to Chargrid 2D. Might be useful here? Getting labelled data might be difficult.
2 Likes
Hi, sorry for the late reply.
If you always have the same document format, text detection with EAST will work.
You might find this useful:
Another approach:
An approche with SSD that works well for your case i think:

Hope it will be of some help!
6 Likes
thanks @Neurosci, I will try them out.
btw, do you think I should extract the document before doing OCR? it is very likely that user will take photo of document with complex background in behind.