Hey everyone!
First time poster, hoping you can help me.
Finished Lesson 05 and wanted to try running my Pokémon Dataset that I have for a project.
I did a very basic loading of my csv through google collab, ran the df through the tabular data loader with a Category block and I am able to define
learn = tabular_learner(dls,metrics=accuracy, layers=[10,10])
However when I either try to find a learning rate or even fit, I get IndexError: Target (whatever index at the time of the error) is out of bounds.
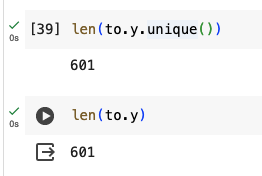
I have checked my dataset and I can’t for the life of me see anything wrong.
Googling hasn’t been very fruitful,
What am I doing wrong?
Here’s the Callback:
0.00% [0/15 00:00<?]
0.00% [0/7 00:00<?]
IndexError Traceback (most recent call last)
in <cell line: 1>() ----> 1 learn.lr_find(suggest_funcs=(slide, valley))
20 frames
/usr/local/lib/python3.10/dist-packages/torch/nn/functional.py in cross_entropy(input, target, weight, size_average, ignore_index, reduce, reduction, label_smoothing) 3057 if size_average is not None or reduce is not None: 3058 reduction = _Reduction.legacy_get_string(size_average, reduce) → 3059 return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing) 3060 3061
IndexError: Target 515 is out of bounds.
If it also helps, please find the Notebook:
https://colab.research.google.com/drive/1iqtqOPmESMJqJizfAMmUjlJPBgq8X2n9?usp=sharing
Let me know if I miss anything, greatly appreciate the help