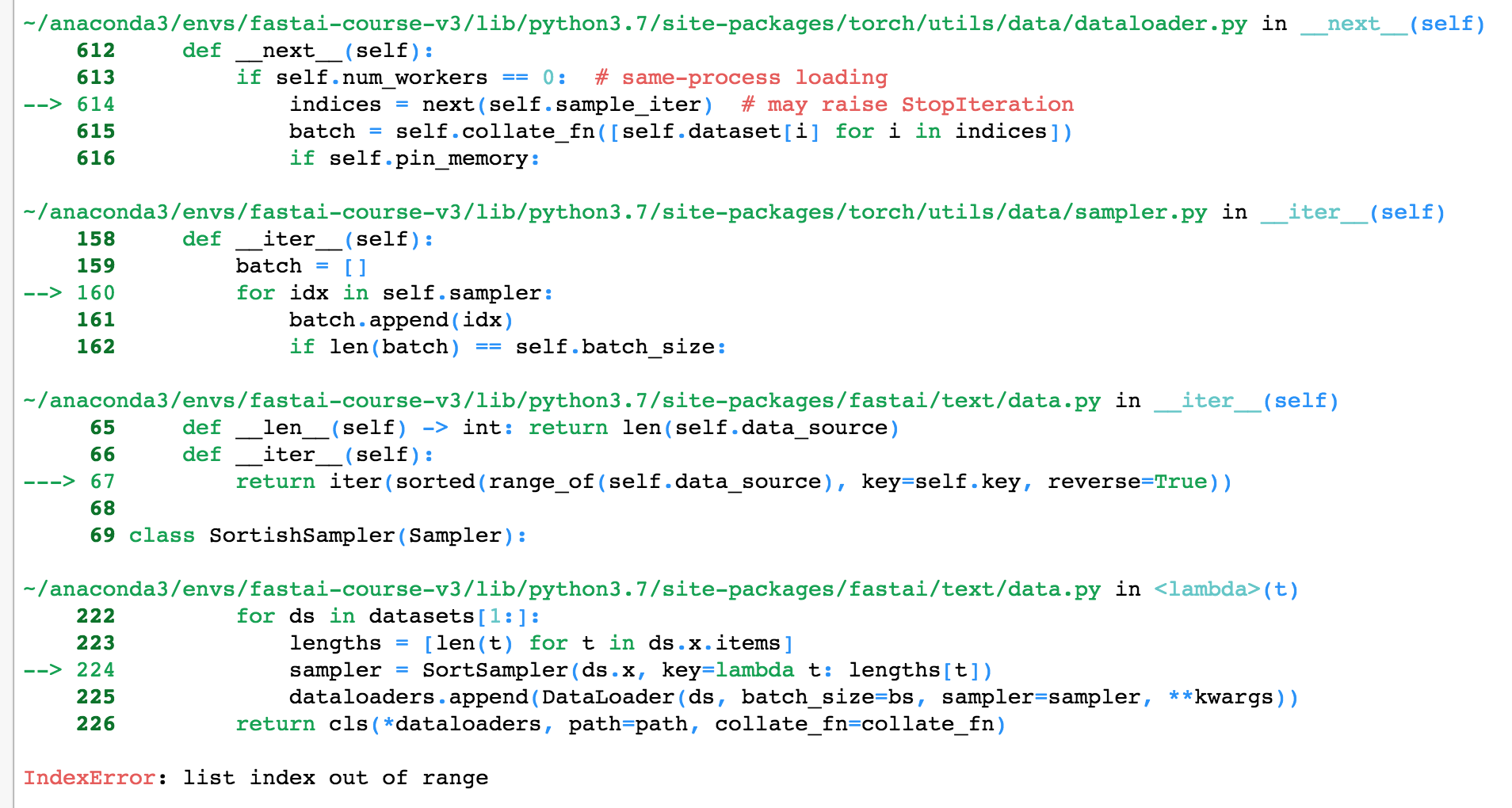
When I run this code below with a sample subset of the data (500k examples) it works fine … but when I run it against the full dataset (train_df has 1,306,122 records) I get an IndexError: list index out of range exception right as fitting concludes, and right before the validation set is processed.
… I get the “IndexError”. But, I don’t get that error when trying to iterate over train_dl or test_dl.
If I take out the .add_test(...) line, then I’m able to iterate over both train_dl and valid_dl.
Am I doing something wrong with the data block API, or is there indeed something wrong with the TextClasDataBunch.create() and maybe also the TextClasDataBunch.load() methods?