Has anyone attempted to apply the concepts from the reusable holdout (Dwork 2015) in FastAI or PyTorch more generally? I’ve been searching for a bit and haven’t seen an implementation.
The idea comes from the academic literature on differential privacy, but the concrete implementation seems simpler. The idea: prevent yourself from accidentally learning too much about the validation set.
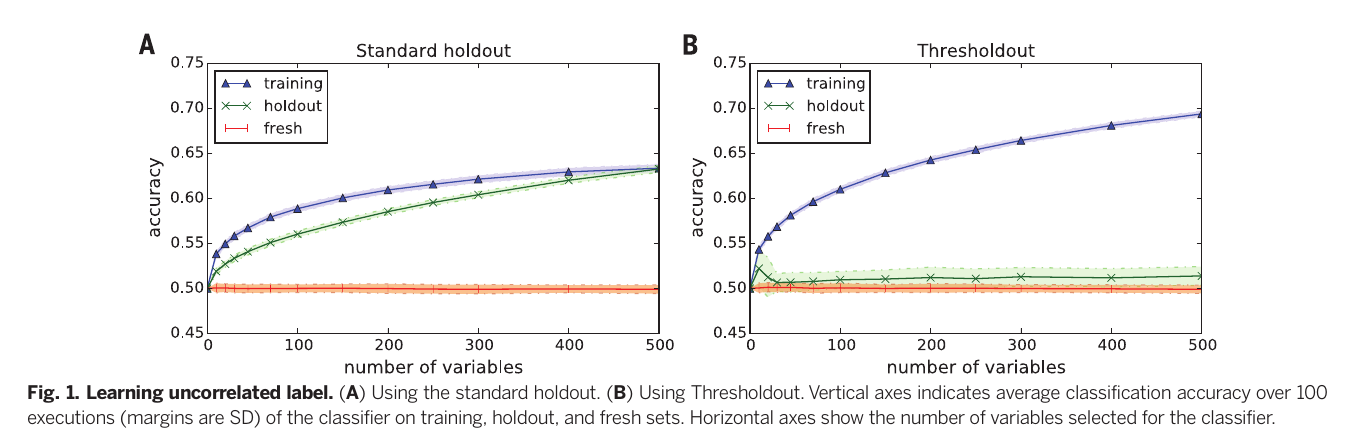
The plot above comes from “learning” random numbers. Any performance over 0.5 is simply overfitting. The usual holdout validation approach is in green on the left, and you can see it overfits. The “thresholdout” or reusable holdout is in green on the right, and you can see that it resists overfitting.
My brief summary of the algorithm is that you don’t simply report the validation loss. Instead, you:
- Check to see if the difference between the validation loss and the training loss is below some threshold. If it is below that threshold, you return the loss of the training set not the validation set.
- Otherwise, return the loss of the validation set plus Laplacian noise
The results (as seen in the graph) are pretty nice, and it seems like it would be great to have this in FastAI as a native tool. I’d of course prefer not to implement this from scratch if there is an implementation in the wild. Anyone familiar?