“The Kaggle training data ends in April 2012, so we will define a narrower training dataset which consists only of the Kaggle training data from before November 2011, and we’ll define a validation set consisting of data from after November 2011.”
This is what is said in the book, and the following code is mentioned below:
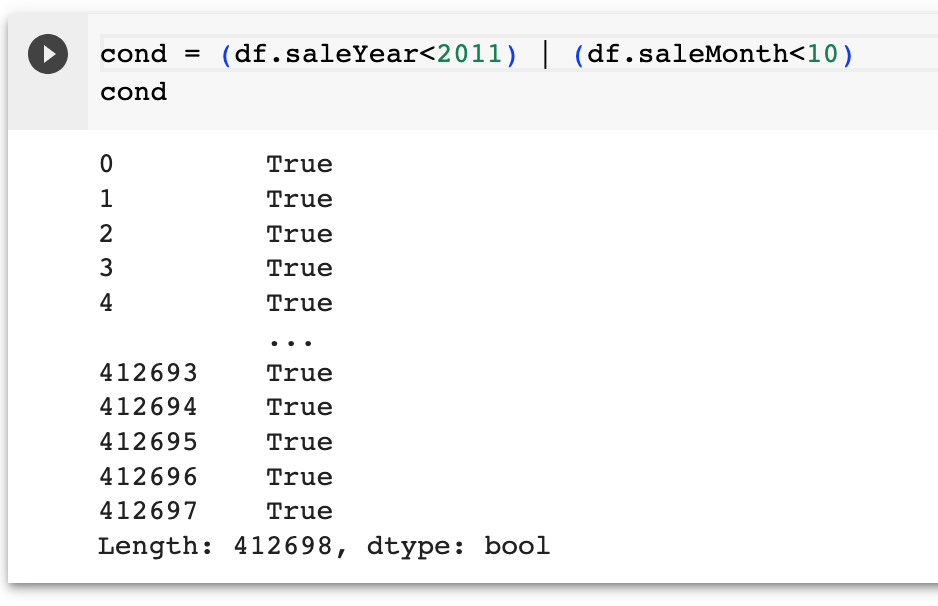
cond = (df.saleYear<2011) | (df.saleMonth<10)
train_idx = np.where( cond)[0]
valid_idx = np.where(~cond)[0]splits = (list(train_idx),list(valid_idx))
So, according to me, it shouldn’t function properly. Since we are using an ‘OR’ operator if even one of them is true then the condition is considered true.
So lets take the case of February 2012 which is in the training dataset and should be a part of our validation set.
So, id df.SaleYear == 2012 and df.saleMonth == 2, we satisfy the 2nd condition of df.saleMonth<10. so this will be in our data training data and not in our validation set.
So technically only data from Nov 2011 to Dec 2011 will come in the validation set.
Can anyone explain to me how the split condition works fine in the book?