Hi, this is my first time posting here. I recently finished the course and just wanted to say thank you for making all these excellent materials available and accessible to everyone! I’m building a small capstone project and have a first working version on HF Spaces, but I need some help improving the quality of the results.
The project
I’m building an app that can automatically generate “Is it really worth it?” memes, like the image below. The goal is: based on an input image, presumably of something human-made (e.g. food or electronics), to find a part of the image that looks like a part of an animal image in a reference dataset, with the tongue-in-cheek implication that the object in the input image was made using animal parts. I have a first working version, but the image matching itself isn’t working very well, so I’d like some help.
Disclaimer: Animal rights are a serious thing and this is just a dumb dark joke - I love animals and I apologize in advance if anyone finds this hurtful. I’m happy to remove the post if people think it doesn’t belong here.
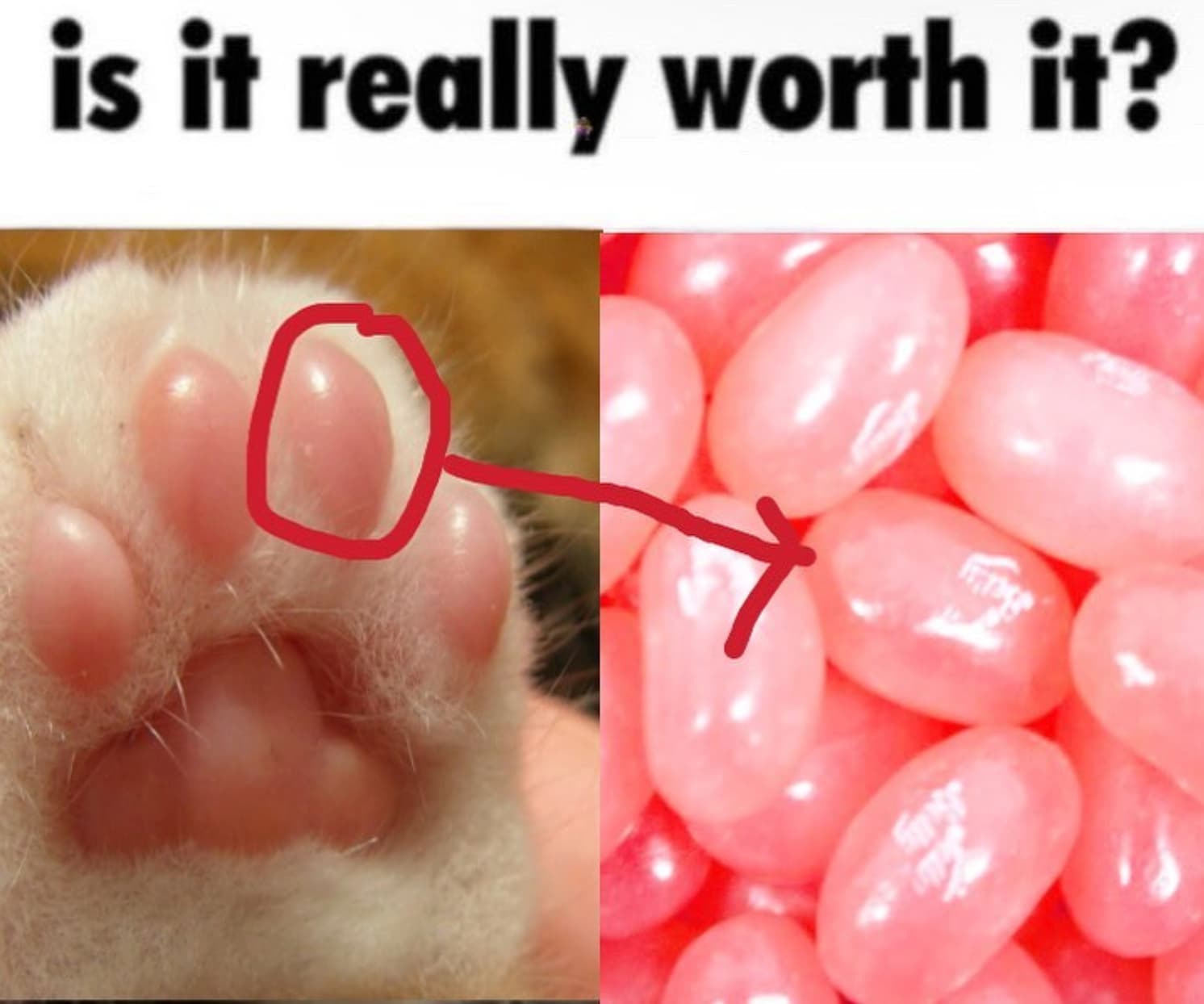
How it works
I have a first working version on HF Spaces here. The code is available in the Files tab. Here’s an outline of how it works:
-
I framed the problem as a retrieval task: given an input image, I want to retrieve the most similar image in a reference dataset. I need 1) a feature extractor that will extract meaningful features from the reference dataset and store them, and 2) a retriever that will extract the same features from the input image, and use some similarity metric to find the image in the reference dataset that’s closest to the input image.
-
I created a custom dataset using two cat breeds and two dog breeds from the Oxford-IIIT Pet dataset and combined them with the Animal Pose dataset. I chose these datasets because they have bounding box / ROI information, which allowed me to create a baseline dataset of animal images without other objects. I stored these bounding-box images (which I’ll call “parents”) in
dataset/parents. -
I want to be able to match parts of the input image to parts of the parent images. I preprocessed the parent images by creating 3 random crops of each image, and storing them in
dataset/crops, naming the files in a way that allowed me to retrieve both the parent image filename and the coordinates of the crop, e.g.dataset/crops/chimpanzee_Img-7840_crop2_17_123_641_653is the 3rd crop ofdataset/parents/chimpanzee_Img-7840.jpg, and the crop coordinates (left, upper, right, lower) are (17, 123, 641, 653). Crop and parent are shown below. The preprocessing script is in

-
To build my feature extractor, I trained a resnet18 animal classifier on
dataset/crops. It trained to about 12% error rate over 10 animal species in 4 epochs. I then created a custom Learner by removing the final layers of the resnet18 (seeiirwi/feature_extractor.py). I usedAdaptiveMaxPool2dto keep only one feature from each of the 512 channels of the final conv layer. -
I extracted the features (i.e. the final
AdaptiveMaxPool2dactivations) for all the cropped images in the dataset. -
I created some basic class logic to implement the retrieval workflow (see
iirwi/retrieval.pyand the modules it imports): the input image is randomly cropped 10 times; for each input crop, I find the most similar reference crop by extracting its features and matching them to the dataset crops’ features using cosine similarity. The input crop-reference crop pair with the highest similarity is kept as the final match. The parent image of this matching crop is retrieved, and crop coordinates are used to show both input and reference parent images side by side with red circles highlighting the matching crops.

Improving the results
As you can see for yourselves by using the Gradio app, anecdotal evidence suggests that the results are pretty bad (see below).
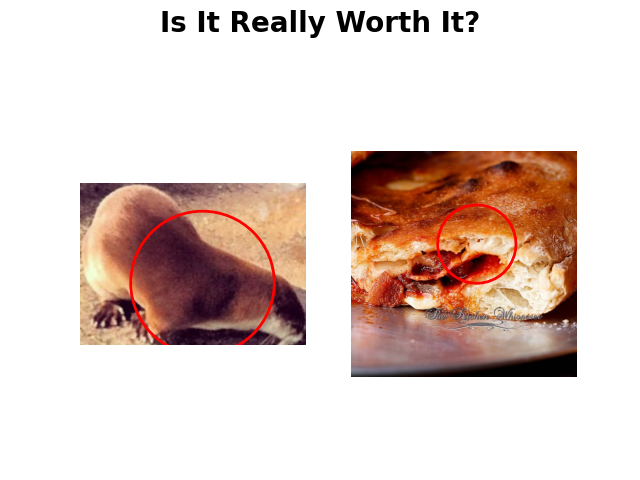
For reference, an earlier version that just matched the entire images instead of crops produced this, which I find a lot better:

Does anyone have ideas on how I can improve the quality of the retrieval? Some thoughts of my own:
- Generating the training set by randomly cropping the parent images means that the images in the training set don’t always contain salient features, and sometimes show e.g. half an ear. Should I try a smarter preprocessing stage to generate the training crops, for example, a model that can find regions of interest in the parent images?
- Should I use a different strategy to turn the resnet18 into a feature extractor?
AdaptiveMaxPool2don the final conv layer gives me basically one number per “feature” the classifier is learning, but maybe I should be using lower level features (i.e. shallower in the resnet) or using AvgPool instead of MaxPool? - Should I try a different architecture altogether? I’m sure there are deep learning models that are designed specifically to match parts of images, with more sophisticated approaches than the one I’m using here.
Any help is welcome! Also curious to hear of other DL projects in the meme world. Thanks a lot in advance.