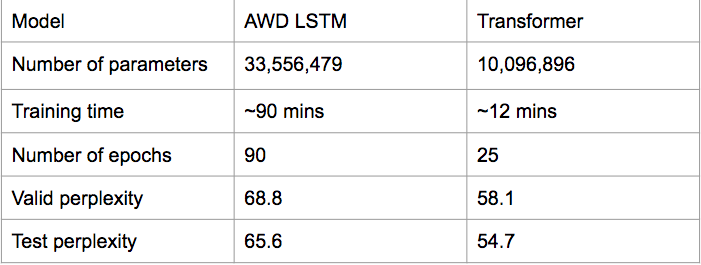
I’ve been doing some language modeling for a research project and wanted to share some progress I’ve made that I find pretty exciting. One of the aspects for my project included implementing a decoder-only Transformer language model, and I wanted to compare it to the AWD LSTM fastai language model discussed in Jeremy and Sylvain’s recent post about AdamW and superconvergence. I used superconvergence to train my model, and only spent about an afternoon tuning my model with the fastai framework (which I have fallen hopelessly in love with at this point). As you can see in the below table, I achieved far better results in much less time, partially because I needed even less epochs and partially because Transformers are convolutional instead of recurrent.
I’ve been super impressed by all the work by Jeremy and the rest of the team. Using fastai for this project has vastly improved my ability to iterate and improve my models. Keep up the great work guys!
I would be willing to discuss more details over PM/email, but I don’t want to share too much publicly at this point because it’s part of an ongoing research project at my lab. We will release the code publicly after we finish and submit our paper to a conference.
Congrats on the great progress! Not at all surprised to see this result - it does seem that transformer architecture has a lot of opportunity. Many thanks for sharing. I’d love to see your code to see how you’re working with fastai.
Oh my gosh! I did not expect to get a reply from THE Jeremy
As I mentioned in reply to Sylvain, I would be more than happy to discuss the details/share the code with you privately, but I don’t want to reveal too much publicly yet as these results are an intermediate result of a larger research project I’m working on.
Congrats! This looks awesome, especially given that after countless times of attempts, the best ppl I got from Wikitext-2 and Transformer is like 150. I got a great result from another dataset that is like 1 Billion Words dataset, though. Did you also experience the same issue? Either way, I’m quite eager to learn from you more details about your findings through email!
@jbkjr Very impressive results. I’d love to see a prepress of the paper when you’ve got results and to see the gist. Any conclusions around parameter settings. Were you able to use @sgugger’s recommended values?
I’m also guessing @sebastianruder is going to be quite interested in this result. He blogged just last month about SOTA perplexity on Penn Treebank. Your model would beat the best, albiet by a small margin, but given the parameter size and training time that’s a big achievement.
Also curious about how you modified the transformer if you’re able to share.
On a related note, I’ve had success finetuning the transformer architecture on Wikitext-2 using the model released by OpenAI as a starting point (https://github.com/openai/finetune-transformer-lm). I’m curious to know if there is an established SotA on Wikitext-2, as all I could find was a test perplexity of 52 from Stephen Merity here (https://arxiv.org/pdf/1708.02182.pdf).
I’m very new to NLP in general, and so I have certainly very possibly made a mistake, but I was (seemingly) able to obtain a test perplexity of 50 on Wikitext-2 in 6 epochs of finetuning the OpenAI model. It took a combination of gradual unfreezing and layer specific learning rates. If I’ve not made a mistake in that score, I’m sure it could be decreased even more because I didn’t spend much time at all tuning hyper parameters. Regardless, I echo the sentiment that the fastai course has been very helpful in learning all this, it’s much appreciated!
@sethah The SOTA result is roughly about 40 with dynamic evaluation or cache pointer and 61 without either of them. One of the SOTA models is in the paper about mixture of softmaxes (MoS). To be fair, your model contains much more parameters than @jbkjr or MoS and was pre-trained on a gigantic dataset, so it’s not comparable. However, it’s good to learn that you can train Transformer on Wikitext-2 without problem.
Great results @jbkjr! I’ve been exploring this area as well and Transformers definitely show a lot of promise in getting equally good/better results for a fraction of time/cost. Looking forward to the paper/code. Do share it here when you’re ready to release it.
Hi,@jbkjr , Congratulations to your project! Currently I am also implementing transformer to test its perplexity. But I have encountered some problems. It seems that unlike LSTM which generates a word based on its privious word, transformer predicts a word based on its all context, which means it can see a word itself when predicting this word. And adding triangle mask didn’t help, because there is linear transformations before attention. So I got a perplexity extremely low and it’s obviously wrong. How do you test perplexity on transformer. Sorry I’m new to NLP and this may be a stupid question to you. But can you help me with that? thank you!