In class Jeremy mentioned his belief that different resizing methods would have an impact on model training time and performance. This is a really interesting question and relevant to me since I’m working on the Fisheries competition and have been using the square images that come from the Keras image data generators. I’m still working on the right approach to answering this question but have a starting point and wanted to open it up for some early feedback. The notebook is available here: https://github.com/ostegm/resizing/blob/master/Resizing.ipynb
As a starting point, I picked out three Methods for reshaping and resizing an image - here’s the original image and examples of each method:
Original Image:

1. “Squashing” - ignore aspect ratio and squash to (224,224)
2. “Center Cropping” - resize the image so the shortest side is 224 but the aspect ratio is unchanged, then center crop the longer side

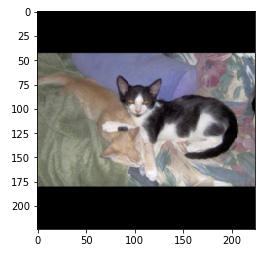
3. “Black Borders” - Add zeros to make the image square, then resize to (224,224)
From here, I took the dogs vs cats data set from part 1 (via kaggle) and generated resized images using each of these methods. Initially, I wanted to train VGG from scratch using each of them, but I decided to start with fine tuning since I knew this would be faster to see some results. Initially, I fine-tuned the fully connected layers of VGG for 30 epochs and compared the validation accuracy of the 3 methods:
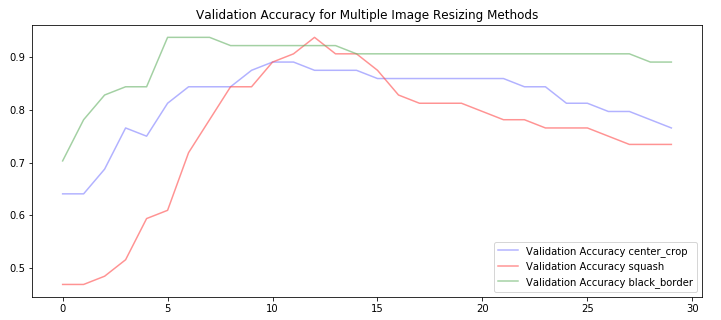
It looks like we do see some differences between the 3 cropping methods, but I wondered how much of that was more the result of the model initialization and “luck” (getting an easy to learn batch first). So I basically redid the step above many times and then looked to see if there was a pattern:
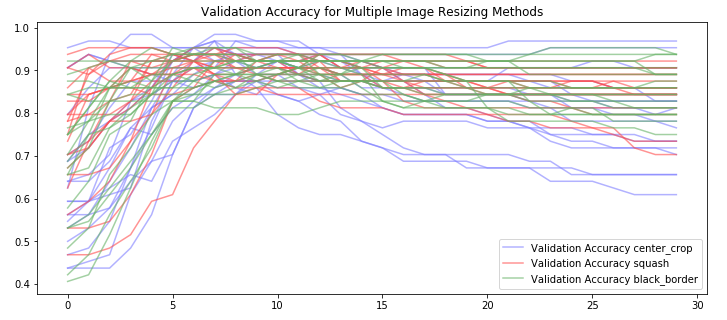
From my perspective, this looks like noise - meaning none of the methods is significantly better for fine-tuning than any other. However theres a lot to dig into here… some questions that come to mind:
- Whats the best way to compare these methods on a level playing field? In reality, someone would be babysitting the learning process (tuning the learning rate, modifying the dropout etc.) - which might lead to better models in the end, but since I’m not doing that here, I might falsely conclude that one cropping method is “worse”
- How do these results differ with a different dataset with a harder task (like fisheries or even imagenet)?
- What would happen if we started from random weights. Would one model converge faster?
- If starting from random weights, should it be VGG (or resnet/inception), or just any functioning convolutional neural network? How does that change things?
I think my next step here is going to be trying to train a model from random weights, but I need to think of clever ways to make the training process faster as well as find a way to compare these on a level playing field I’d love any questions, comments or suggestions on those topics, or any other ideas!