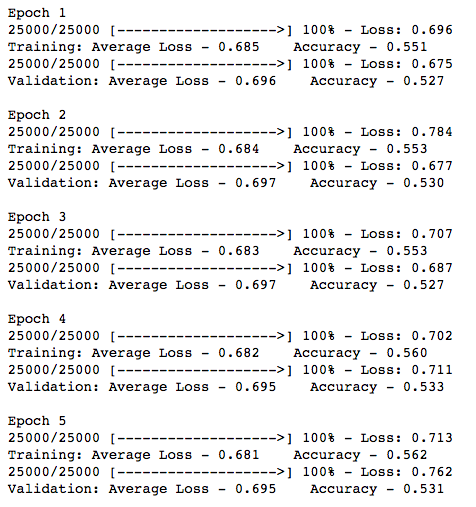
I have been trying to replicate some of the notebooks in the fastai course in pure PyTorch(to understand more whats happening behind the scenes). I am currently working on the IMDB dataset. However, I have been unable to get an accuracy of higher than 60%.
In the lesson3-imdb notebook, the classifier was able to achieve an accuracy of 94%. Are the results that I got normal, or is something wrong with my code? (Note that I am using a normal RNN, without GRU or LSTM).
Glancing through the notebook it doesn’t look like you’re applying any of the fastai techniques; so you’re not going to get the same results:
Your network is a lot smaller (in terms of embedding size and number of dimensions) and simpler (no LSTM, no dropout).
It doesn’t look like you’ve got a pretrained language model on Wikitext-103
It doesn’t look like you’ve finetuned a language model before transferring to classificaition
It looks like you’ve done a good job of importing the data and creating a basic PyTorch model; but if you want fastai results using just PyTorch you’re going to have to apply the same techniques.
Read the fastai source code and experiment with it to see how it all works; I like how it abstracts away a lot of the complexity (loading in data, training loop, etc.) but lets you customize it.
I understand that the 94% accuracy achieved in lesson3-imdb was due to transfer learning. However, will using a simple RNN with randomly initialized weights(no pretrained model) get the same results that I did? I’m wondering because I want to check if my code has a bug, or if this accuracy is normal.
The base RNN model wasn’t even as good as yours. Maybe you can start with a good working model with LSTM and see how accuracy changes as you start taking features away, until you’re back at a simple RNN.