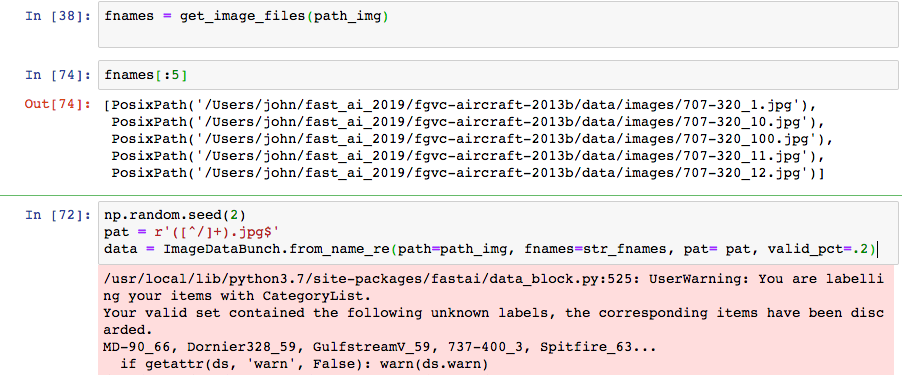
I’m following along with Jeremy’s Lesson 1 notebook in intro to ml for coders, using a prepared dataset. I’ve organized my dataset to match the pets dataset used in the notebook, so the files are arranged as follows:
image_type_a_0.jpg, image_type_a_1.jpg …
image_type_b_0.jpg, image_type_b_1.jpg…
… etc.
I then attempt to load an ImageDataBunch using from regex function, and get the following error:
Hi jecker7,
I see that your re doesnt remove the last part with underscore and the digits. Not sure why but even the Pets dataset gets same error when I remove ‘_\d+’ from re.
Let me know if this helps.
Yes it was the regex. The reason is the capture group from the original notebook grabbing everything outside of ‘_\d+’ , changing the regex was a mistake on my part. With the capture group I have shown, every image file is treated as a separate group.