Hi!
I would like to implement a model for face-image verification using a siamese twins. So I get an image of a person and compare this to all possible images. I think this should work but I also think this would not be the smartest possible idea. What do you think? Thanks!
This is a very common usage of siamese network. If you just google ‘siamese network’, there are quite a lot of articles/resources that talk about it, including different variants of the networks and loss functions used.
Good luck, and have fun exploring this!
Yijin
1 Like
Stuck with Siamese Network for Face Verification.
Hi! I have found a tutorial on the fast.ai site on how to implement a siamese network: http://dev.fast.ai/tutorial.siamese
I reworked this tutorial for face-verfication with the at&t face data set. In theory it works and validation accuracy is above 97% but it completely fails with additional test-data. I have created a set of portrait image of two different people. With the test-data images I achieve accuracy about 50% which means the model is completely useless. I could just throw a dice as well.
Here is a link to my notebook: https://github.com/we-make-ai/siamese_face_verification/blob/master/Siamese_Face_Verification.ipynb
Do you have any ideas on how to improve the quality?
I think of these two paths:
- I think there aren’t used any additional transforms like contrast, resize, etc. in the tutorial
- The training and validation images are greyscale, the test images are colored image
…?
Thanks
Edit: I have changed my test images to greyscale, seems to improve test-quality a bit.
Hi,
Firstly, just want to check, you mentioned 97% validation accuracy, but I can’t seem to see/find that in your notebook? I see ~81% accuracy after 10+20 epochs?
In any case, there are a few things that I can think of and comment on. (Disclaimer: I have no idea/proof if what I say below is correct or not…! =P )
I cannot remember off the top of my head what augmentations were applied in the tutorial within after_batch by just using fastai2’s aug_transforms. Your notebook seems to have defined your own set of augs, namely Rotate, Flip, Warp, Zoom, Contrast, Dihedral, and you can always try out different (additional) augs that you think make sense and might improve performance.
Yes, I think coloured vs. greyscale will definitely affect a lot of things, and among other reasons resulted in the output that you got. I will write down some further thoughts about these below.
- The example Siamese network backbone uses resnet34 pretrained on imagenet, and so there will be quite some differences between the high-level ‘features’ it recognises (chiefly to do with classifying 1000 imagenet categories of coloured images) and the ‘features’ you need for recognition/classification of greyscale facial images, which require more granularity and subtlety in facial features. When you then gave it test set of coloured images again, it’s kind of like ‘triple-confusing’ to the model (pretrained on colours; finetuned on greyscales; tested on colours)…
- Due to the differences, I think you will need to train the model for more epochs in its unfrozen state, to learn to differentiate features between greyscale faces. One key benefit of the Siamese network is that from a relatively small set of training data you can already generate a lot more ‘pairs’ as training input, and so I think you can train for a lot more epochs.
- Having said the above, at the end of the day it seems like you only have 40 people ×10 images each for training data, and I don’t have sufficient experience to say whether that’s enough for the model to learn the subtleties in facial feature differences or not. (It looks like it’s not enough)
As far as I know, the typical usage for such ‘face verification’ Siamese model would be:
- Have a list of identities that are intended to be matched against in deployment, e.g. a ‘staff database’ of 50 people, each providing a few headshots to the training set.
- Generate Siamese-pairs from the data and train the model to learn the feature differences, which is actually still somewhat ‘specific’ to the headshots of the database of identities.
- In deployment (i.e. the ‘test’ stage), feed it an input image, and use the Siamese network to compare it with each of the 50 identities in the database (in batch in GPU if useful), to say whether the input is from one of the identities. I guess if necessary it is possible to ‘ensemble’ this test to compare against multiple images of each identity and perhaps get a better output prediction.
- If there are now new staff, add their headshots into the data set and either retrain altogether (if doable) or just train the saved model more with the new, larger, set of data. In ‘test’ stage, add the new staff into the reference list of images to be compared (now >50 identities).
In your notebook, your ‘test’ is to use the model (which might not have been sufficiently trained, to begin with) to differentiate between two new identities that the model had not seen before. I think this is somewhat different to my understanding of the typical process/usage mentioned above. Add to that the differences in the pretrained features and coloured (pretrained) vs. greyscale (your data), and possibly the low epoch count, I think they all combined to give the low test accuracy that you saw.
I think if you are looking to have a Siamese network that can output ‘similar/dissimilar’ for new images/identities, you will likely need to have a lot more training data (in terms of both variety, i.e. number of identities, and volume, i.e. number of headshots per identity) for the network to actually learn, when trained a lot more in unfrozen state, all the subtleties in facial features. You should also look into different types of loss functions (I think there are ‘triplet loss’ etc.) and ‘similarity metric’ (with threshold) as output, instead of just a probability.
As an aside: I previously mentioned to Sylvain that the tutorial you linked to does not actually implement a common/typical Siamese network model, e.g. it does not do a ‘difference in activations’, but instead concatenates the two sets of activations together for the ‘head’. In a way, I think it shows the power of fastai, where a quick and easy custom architecture (Sylvain did not actually read too much into Siamese network, he kind of just winged it!) can still give pretty good results! One downside is that the model is not ‘symmetrical’, i.e. the input of [img A, img B] will give a different output from [img B, img A], even though we are nominally looking for a single output of ‘how similar is this pair’.
On the other hand, if you are looking for the more typical application of ‘is this image one of my staff’ that I mentioned above, then your ‘test’ stage will be comparing against images of identities that the model had already seen and been trained on, and should give decent accuracy, plus all the benefits of Siamese network (not needing large data set, easier to extend to more identities, etc.).
Hope this helps. Apologies for the ramblings - wasn’t planning to write so much…!
Yijin
2 Likes
Hi! Thanks for this very detailed answer! I have definitely got some points to work on.
What’s your advice on getting this “A - B” is like “B - A” difference in activations into the model?
Would you suggest to use another another model than resnet34? (I have to admit, by now I not that familiar with using differnent models with fast.ai)
Thanks!
I guess just change the custom model and take the (absolute) difference, instead of concatenating? I think it needs to be abs difference so that it is indeed symmetrical for A-B and B-A.
I wasn’t suggesting that you change to a different pretrained model here – resnet34 is normally a good one to start playing with. I was just saying that an imagenet-pretrained model (e.g. resnet34) will not, by default, suit the application that you have in mind, and you will need to train for more epochs and with more relevant data (e.g. greyscale facial images) first. You can also search around for more relevant pretrained models that might be useful for you to experiment with – a quick search returned something about ‘OpenFace’ pretrained model.
Good luck!
Yijin
Hi @utkb,
Im currently working with the siamese tutorial with my data. I want to replace the current head+loss of the tutorial (concat embs+linear layers+cross entropy) with other types of metric learning approaches. Im new to metric learning. What are the common approaches (and SOTA) to deal with the pairs of embedings in a siamese model?
- Absolute difference of embs -> linear layers -> binary classification
- Cosine similarity of embs -> regression
- ArcFace loss
Hi Javier,
My quick (read: simple =P ) tests showed that the abs-diff approach gave similar performance as the concat approach that Sylvain took in the tutorial, except the concat approach is not ‘symmetrical’ as I mentioned above.
Unfortunately I haven’t actually had time to look into more details for these. I previously bookmarked this link, which seems to give pretty good coverage of different loss function approaches for metric learning, including some links to implementations in different frameworks (e.g. PyTorch). As far as I could tell, one key thing would be the selection/tuning of the ‘margin’ value, which seems somewhat analogous to tuning ‘threshold’ value, depending on what you value more (precision, recall, FP, FN, etc.).
It would be super interesting to read more about what you find from your work.
Yijin
1 Like
I know there is a package called pytorch-metric-learning with a lot of losses (potentially useful for siamese tutorial i think) and miners (Mining is the process of finding the best pairs or triplets to train on)
I want to bring some losses to the fastai2 siamese tutorial
1 Like
Great to see that there are more guys interested in the this topic!
I am currently experimenting with a bigger dataset.
I have extracted the faces from this dataset from google: https://research.google/tools/datasets/google-facial-expression/
cleaned to have each face only once in the dataset and augmented each image by setting different contrast and/or rotations.
This created a dataset with 86281 different face images and a total count of 2674176 images for training and validation.
Yet the code from the tutorial to extract the image-names as keys of a dict was extremely slow:
labels = list(set(files.map(label_func)))
lbl2files = {l: [f for f in files if label_func(f) == l] for l in labels}
My “new” dataset is organized into different folders. There is a distinct folder for each category and I found that scandir works a lot faster (see # https://stackoverflow.com/questions/800197/how-to-get-all-of-the-immediate-subdirectories-in-python)
def label_func(fname):
return parent_label(fname)
path = Path()
img_path = path/"google_face_images_dataset/"
files = get_image_files(img_path)
list_subfolders = [f.path for f in os.scandir(img_path) if f.is_dir()]
re_pattern = r"^.*\/([^/]*)$"
lbl2files2 = {str(re.match(re_pattern, l).group(1)): [Path(f.path) for f in os.scandir(l)] for l in list_subfolders}
labels = list(lbl2files2.keys())
Just in case this helps anyone.
1 Like
It seems like a bug has been spotted in the Siamese tutorial, see here. It relates to ‘leakage’ between training set and validation set generation. Prudent to review any code and work that might be based on the tutorial.
Yijin
Hmm. Added a new comment to the Github issue, copy-pasted below.
Actually, having thought about it a bit more, does it matter that the second image in the Siamese pair, which is the ‘reference’ to compare with the first image (from validation set), is in the training set? During inference, you would be feeding the trained model a test-image and a reference-image (known class/category) anyways, right? And so the validation-set is being used in a similar way, i.e. comparing the validation-image with a reference-image (known class/category from training set), right? Interested to hear from others who have more knowledge and experience in this…
Yijin
This bug in the fastai (v2) siamese network tutorial has now been fixed and merged, using the code provided by the bug/issue OP on Github : )
Yijin
Problem with predict method.
When I call predict I get this error message:
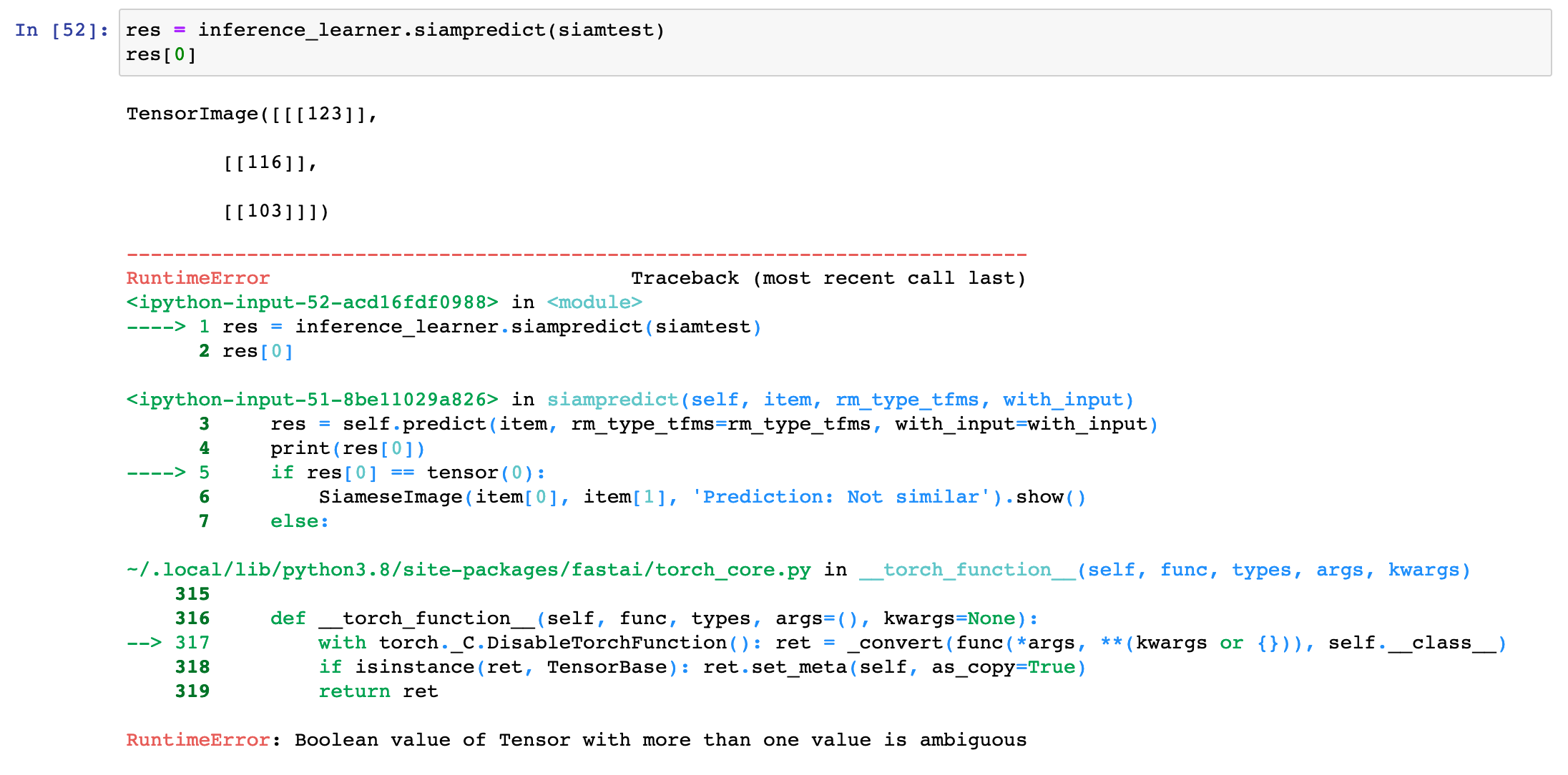
So why do I get a tensor image? I have looked into the source code of predict:
def predict(self, item, rm_type_tfms=None, with_input=False):
dl = self.dls.test_dl([item], rm_type_tfms=rm_type_tfms, num_workers=0)
inp,preds,_,dec_preds = self.get_preds(dl=dl, with_input=True, with_decoded=True)
i = getattr(self.dls, 'n_inp', -1)
inp = (inp,) if i==1 else tuplify(inp)
dec = self.dls.decode_batch(inp + tuplify(dec_preds))[0]
dec_inp,dec_targ = map(detuplify, [dec[:i],dec[i:]])
res = dec_targ,dec_preds[0],preds[0]
if with_input: res = (dec_inp,) + res
return res
Shouldn’t be the decoded label the first argument with res?
I am really stuck because I can’t figure out, why predict returns a tensorimage?
By the way, has anyone managed to build a robust image recognition system with siamese twins - deciding if two images are the same?
I have now retrained my model with 2,674,176 face images. 20 augmented images for each distinct image. Yet my model is below a random classifier.
Your screenshot seems to show that your siampredict is not the same as the one in the tutorial notebook. What modifications did you make, that are not shown in the screenshot?
One difference I can see is that you have with_input=with_input, instead of the with_input=False in the tutorial notebook. So, if your with_input arg is set to True, then predict will add dec_inp (the decoded input) to the front of res, thus giving you TensorImage in res[0].
As a quick test/fix, you can set with_input back to False when calling siampredict, and see if it all works. I would also advise you to review the code changes you made, e.g. to siampredict, against the tutorial notebook, to make sure you understand what and why you made those modifications.
Yijin
1 Like
I think the tutorial notebook already showed that a robust model can be created using a siamese network? The results shown in that notebook look pretty good…!
With your >2mil images, how many classes (people/identities) are they from? It sounds like a decent-sized dataset, so you might not even need to augment. I would be surprised if a trained model performs worse than random… Have you tried just swapping in your own dataset to replace the oxford-pet dataset in the tutorial notebook, without changing anything else? I would imagine after similar training it’ll still do a decent job with your data – most probably better than random…!
If you are making more changes and building your own network/model/code changes, try to start small (not with your full >2mil images…!) and build up from there?
Yijin
1 Like
This is my full siampredict methode:
@patch
def siampredict(self:Learner, item, rm_type_tfms=None, with_input=False):
res = self.predict(item, rm_type_tfms=rm_type_tfms, with_input=with_input)
if res[0] == tensor(0):
SiameseImage(item[0], item[1], 'Prediction: Similar').show()
else:
SiameseImage(item[0], item[1], 'Prediction: Not Similar').show()
return res
I just pass the parameters from siampredict to predict. I think this makes more sense because otherwise I could set rm_type_tfms and with_input when calling siampredict but it would not make any differences to the call of self.predict.
I have also tried the AT&T facial images Testset with only about 40 images. Then I have also got bad results and wanted to try a bigger dataset.
Therefore I use the google facial expression dataset: https://research.google/tools/datasets/google-facial-expression/
Perhaps I am following a misleading trail when creating the dataset:
- The dataset contains facial images and annotations on the facial emotions as well as coordinates of a facial bounding box.
- I use the bounding box to cut just the facial portraits.
- I save the distinct portraits in seperate folders (categories) and apply 30 random transforms like modifying contrast and rotating the images.
- I end up with 86,282 distinct labels and a total of 2,674,176 images.
Perhaps I have too many categories with too less images in each of these categories?
Do you know any good dataset for training a face recognition model?
Javi, did you ever make any progress on introducing these losses to the siamese tutorial? I started a related thread here showing my work in progress.
1 Like
No, metric learning is still a pending topic for me. I have found that best resources for this type of models are Kaggle classification competitions with:
- lots of classes
- few samples per class
- umbalanced classes