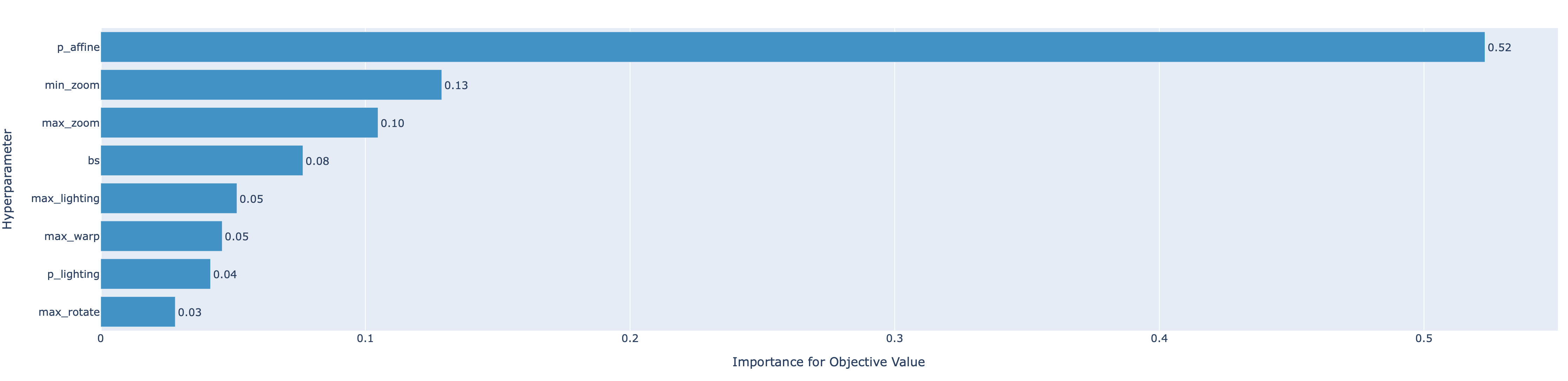
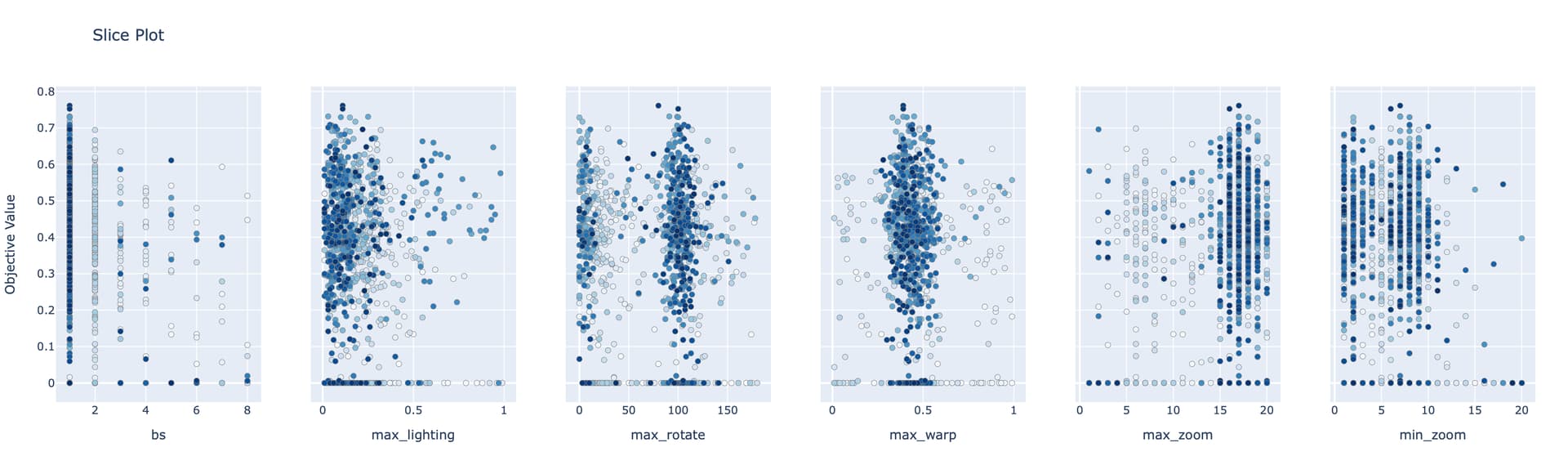
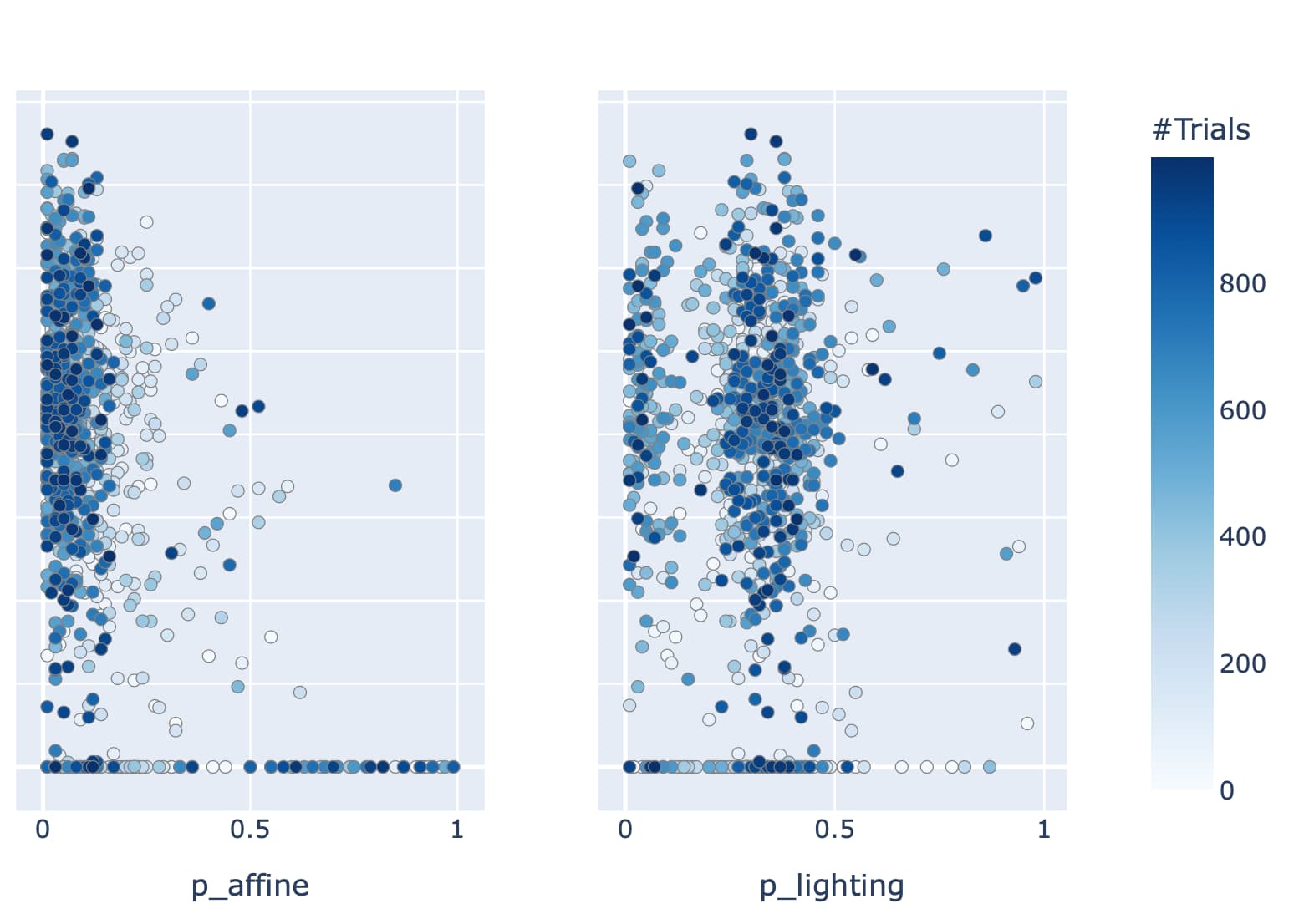
Short version: Is it possible to leave some pixels unlabeled when training a segmentation model? If so, how would I specify “unlabeled” when creating the mask?
Long version: I am hoping to train a segmentation model to classify vegetation cover types in aerial imagery. I will need to create my own labeled masks to train the model, and I am thinking about ways to do this quickly and efficiently. One option would be to only label some of the pixels in the image, such as the ones that are easiest to draw polygons around, or even just a few “representative examples” as opposed to every single pixel. Here is an example of how I would like to be able to label an image:

Is there a way to assign pixels a “no data” value so they are not considered in the fitting of the model? I don’t think it would work to create a new class called “unclassified”, as this would cause the model to get confused between the labeled features and the unlabeled features that are actually of the same class as some of the labeled features.
Thanks in advance for any help!