I’m trying to use the feature loss technique described in lesson 7 to build a inpainting U-net on the Pets dataset. This are the results I’m currently getting:
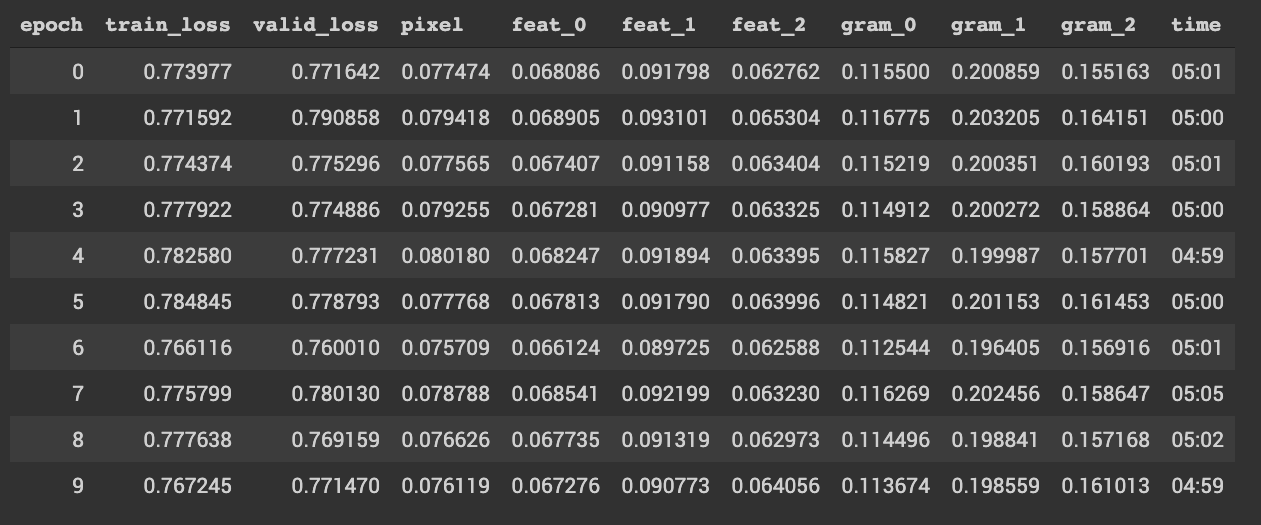
I’ve trained the models for some hours and the loss plateaued. As we can see, the results are not good but they are on the right track, but for some reason we see this very pixelated result.
Is this normal for this kinds of problem or there might be something very obvious I’m doing wrong?
In the class Jeremy defines the crapify function and run it once on the entire dataset before training starts. Instead of doing that I defined a custom transform that lazily adds the boxes in a random order on each batch of images. I thought that was a good idea because I would have very different box positions for each image. But maybe that is leaking information on the training set and it’s causing the model to not learn correctly?
Here’s the source code in case anyone is interested.
Your loss jumps a lot after doing unfreeze, it got worse and didn’t recover from your first training part. Try checking the predictions without that part. Also try not using .to_fp16(), as it can make it more unstable. Tried to test it myself but the path/‘small-256’ part is missing
I’ll try removing .to_fp16() but I’m not very helpful that this is going to change things dramatically.
As far as the losses go, the results on the notebook might be misleading, I don’t tend to run my nbs in order, so what happened there is that I double the image resolution and started training again. (Just like we did in planets in class).
If you still interested in running the code you can replace path/'small-256' with path/images, it will not make a difference since we’re rescaling the images with the databunch anyways.
I have not tried that, I’l try and report the results.
I tried this Resnet version on the same project as we did in class and I got very similar results (even a little bit better) with faster training times.
Still blurry but better coloring yeah. Resnet instead of vgg might work, but not sure which layers you should pick. How is the metrics table looking like now?
checkerboard pattern: This usually means that the upsampling in your generator is not perfect. You probably have some Deconv layer in it. You can try different upsamples there. For example some F.interpolate followed by a normal Conv2d. (But that introduces other artifacts usually.)
Missing long range dependencies: People ofthen mention SelfAttention layers in this case.
It could be useful to have a look at the DeOldify project, too.
I’ll definitely take a look at the DeOldify project.
The truth is that I’m not currently understanding 100% of what is going on here, I know Jeremy explains U-Net on part 2 so hopefully things will be clearer by then.
But I do remember Jeremy saying that self-attention was important for this kind of problems, and mine was turned off, I’ll try that and report the results again.
Let me ask you for your advice as well, do you think self attention will significantly improve my results? Do you think it’s possible to achive something that at least “looks good” with this Pet dataset?
And also, any ideas why the checkerboard pattern was much stronger in the resnet version? Before this experiment I tried to use resnet in the same experiment we had in class and the results were even better than vgg.
Let me ask you for your advice as well, do you think self attention will significantly improve my results? Do you think it’s possible to achieve something that at least “looks good” with this Pet dataset?
I’m bad at these predictions. The right answer is always you have to try One thing I would try is: Start with small boxes and see how big you can make them with “good enough” results. Hopefully you can make bigger boxes with SelfAttention.
And also, any ideas why the checkerboard pattern was much stronger in the resnet version? Before this experiment I tried to use resnet in the same experiment we had in class and the results were even better than vgg.