This was really just an exercise in learning to write fastai Callbacks, but it’s intriguing:
On the Discord “chitchat” channel, I was getting some wonderful, very detailed help from @Ezno and @ilovescience in trying to answer the question:
How would the suggestions of the LRFinder at every batch (during training) compare with the profile of the 1-cycle schedule? Would they be similar or very different? (e.g., would you ‘naturally’ get something like cosine annealing?)
This was just an exercise in “understanding,” not a practical idea. Calling lr_find() at each batch is incredibly slow, and… as we’ll see… makes something bad happen.
With the help of those guys, I was able to write my first two fastai Callbacks! The first was just a sanity check, and the second would call lr_find() (thanks again to @ilovescience with the syntax!):
class LRTracker(Callback):
"Exercise for self: save learning rates to plot later"
# should give the same results as learn.recorder.lrs
def before_fit(self): self.lr_list = []
def after_batch(self):
if self.training: self.lr_list.append(learn.opt.hypers[0]['lr'])
class LRDriver(Callback):
"Replace LR schedule by calling LRFinder for each batch (slow)"
def before_fit(self,**kwargs): self.lr_min_list, self.lr_steep_list = [], []
def before_batch(self, **kwargs):
if self.training:
lr_min, lr_steep = self.learn.lr_find() #which automatic lr do you want?
self.lr_min_list.append(lr_min)
self.lr_steep_list.append(lr_steep)
#self.opt.set_hyper('lr', lr_steep) # here's where we overwrite the lr
^that last line was commented out because I wasn’t ready to fully implement over-writing the LR schedule yet.
I put this in my copy of the 022_Imagenette notebook on Colab, and when I finally ran this with the LRDriver() callback enabled,… stuff crashed:
learn = Learner(dls, xresnet34(n_out=10), metrics=accuracy, cbs=[LRTracker(),LRDriver()])
learn.fit_one_cycle(5, 1e-3)
0.00% [0/5 00:00<00:00]
epoch train_loss valid_loss accuracy time
0.00% [0/147 00:00<00:00]
0.00% [0/1 00:00<00:00]
0.00% [0/147 00:00<00:00]
0.00% [0/1 00:00<00:00]
0.00% [0/147 00:00<00:00]
0.00% [0/1 00:00<00:00]
...about 50 more lines of that and then...
0.00% [0/1 00:00<00:00]
0.00% [0/147 00:00<00:00]
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/torch/serialization.py in save(obj, f, pickle_module, pickle_protocol, _use_new_zipfile_serialization)
371 with _open_zipfile_writer(opened_file) as opened_zipfile:
--> 372 _save(obj, opened_zipfile, pickle_module, pickle_protocol)
373 return
376 frames
RuntimeError: DataLoader worker (pid 4279) is killed by signal: Killed.
During handling of the above exception, another exception occurred:
RuntimeError Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/torch/serialization.py in __exit__(self, *args)
257
258 def __exit__(self, *args) -> None:
--> 259 self.file_like.write_end_of_file()
260 self.buffer.flush()
261
RuntimeError: [enforce fail at inline_container.cc:274] . unexpected pos 55877568 vs 55877456
So, might anyone have a suggestion for helping this ‘crazy’ idea not crash the DataLoader, etc?
Thanks!
EDIT: …ohhhh I think I see the problem: Since the LRFinder is attached to the same Learner as the one I’m training, all the events are clobbering each other, maybe? I wonder if I could clone the Learner each time before calling the LRFinder…?
 As in so far, 40 minutes for one epoch of Imagenette on Colab, 1 hr on my laptop (RTX2070 Max Q),…but my 3080Ti is burning through it ok – guess I should turn on mixed precision to make this go faster.
As in so far, 40 minutes for one epoch of Imagenette on Colab, 1 hr on my laptop (RTX2070 Max Q),…but my 3080Ti is burning through it ok – guess I should turn on mixed precision to make this go faster.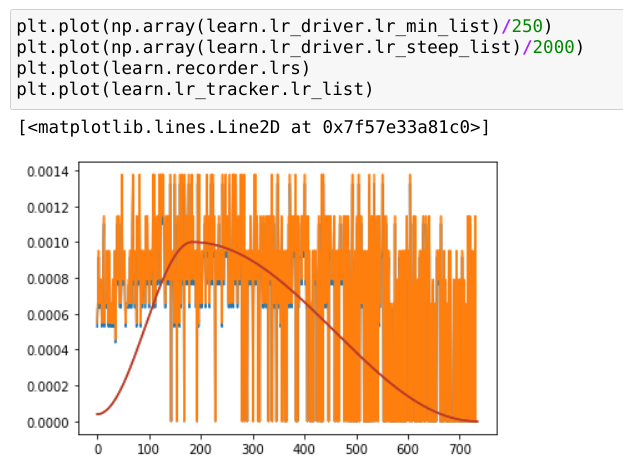
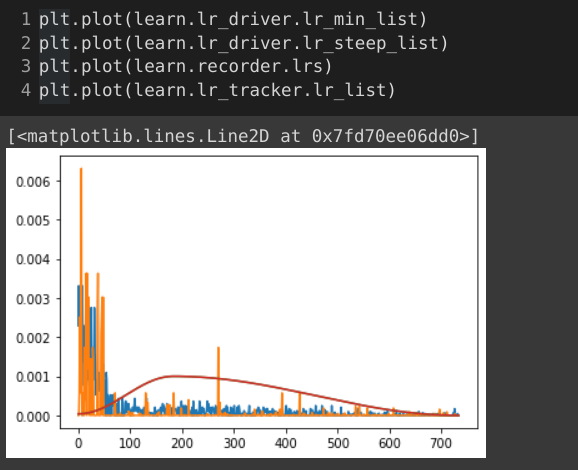
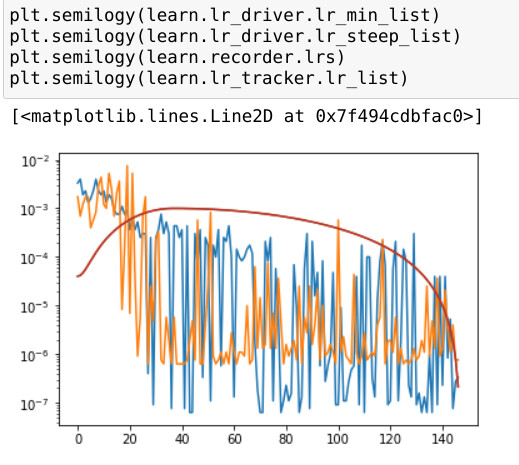
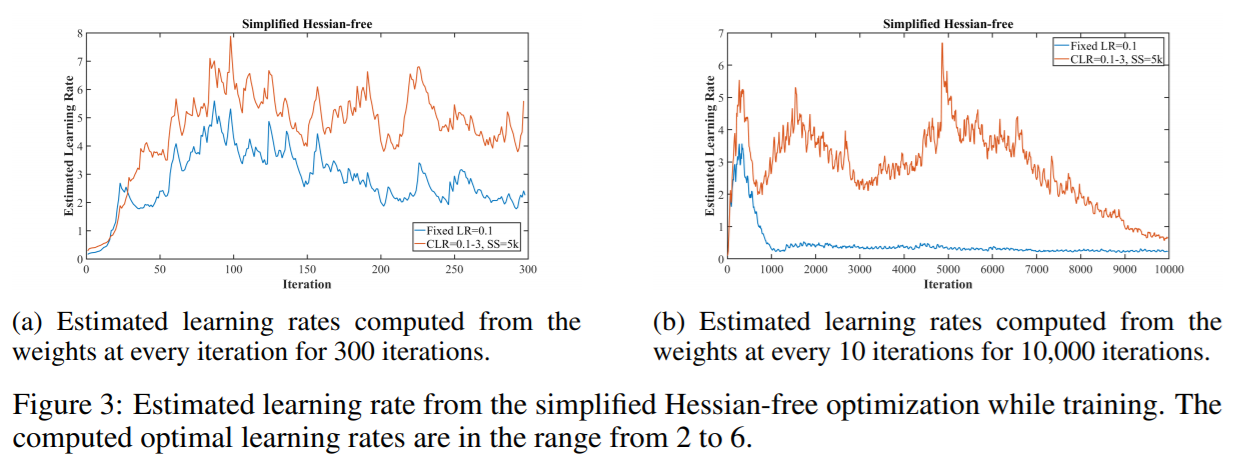
 If I’d read that, it would’ve saved me some time & speculation. The blue line on the right in (b) sure looks similar to what I was getting.
If I’d read that, it would’ve saved me some time & speculation. The blue line on the right in (b) sure looks similar to what I was getting.