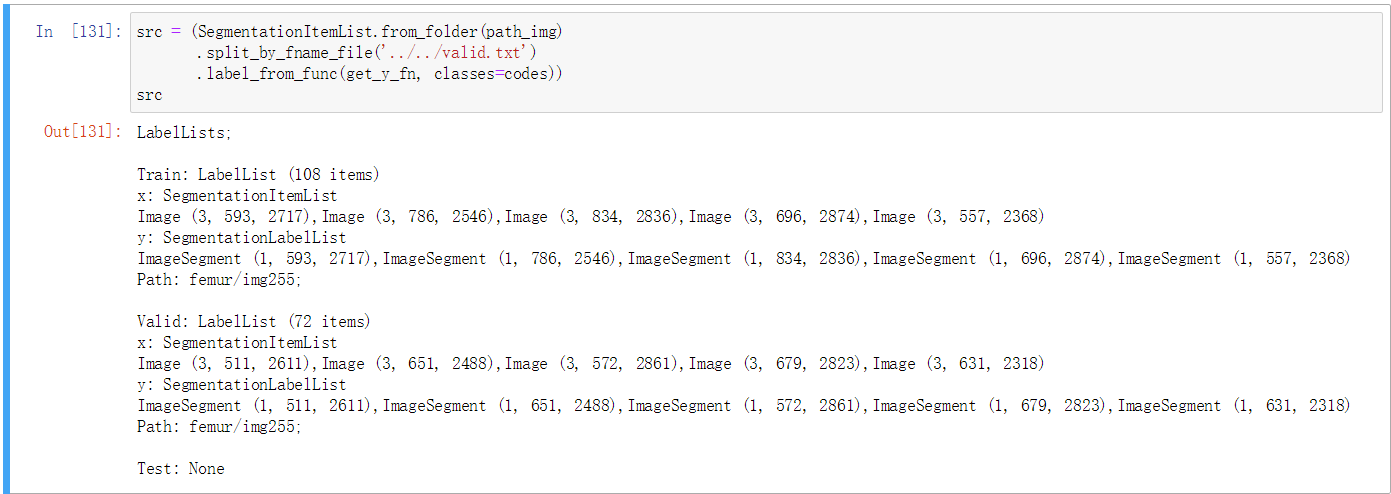
As you see from the picture above, there are different sizes of validation images. And I want to keep them the way they were.
So I set my custom transform tuple where there is no transform for validation. But I do want cropping on training images. So I set rand_crop and size = 256 for training set.

But after I build the databunch and check data.valid_ds, validation images all become size 256. Why is that?
When you pass size=size in your dataWithVal, it automatically resizes things in your validation set as well (not that you won’t be able to build batches if not but I see you set the validation batch size to 1). You need to proceed the same way to remove the transforms on your validation dataset (forgot how to do this in v1).
So how should i call the datablock api so that I could randomly crop 256-sized patch during training but leave the validation images as they were.(I set validation set batch-size to be 1 because my validation image have different size.Clearly they cannot form a real mini batch)
This is not possible in general in the call to the data block API. Although in this case, I guess you could try tfm_y=False, this should do nothing to your targets.
Well this is a little bit awkward. The situation is I use unet to do high-resolution medical image segmentation,which are of size thousand-by-thousand. Training on whole-sized image won’t fit in gpu memory.Also,I don’t want to resize the images because manual downsampling and upsampling will make the prediction mask noisy. So I build a unet that takes 256*256 images.This is why I need cropping during training.Also I suppress the raw validation and wrote a custom validation callback that crop the images and predict on those small patches separately and finally stitch the result together. This is why I need original-sized validation images.