I am trying to follow the book on training the model to recognize threes and sevens. There are two versions of the code, one starting from scratch, and the other is the “optimized” version using classes like SGD and nn.Linear.
The first one turns out to be ok with a 1.0 learning rate, but with the optimized version, a very strange thing happens: the gradient suddenly becomes zero and my model stops optimizing at only about 50% accuracy and I don’t know what’s wrong. Here’s the code:
import fastbook
fastbook.setup_book()
from fastai.vision.all import *
from fastbook import *
path = untar_data(URLs.MNIST_SAMPLE)
Path.BASE_PATH = path
threes = (path/'train'/'3').ls().sorted()
sevens = (path/'train'/'7').ls().sorted()
seven_tensors = [tensor(Image.open(o)) for o in sevens]
three_tensors = [tensor(Image.open(o)) for o in threes]
stacked_sevens = torch.stack(seven_tensors).float()/255
stacked_threes = torch.stack(three_tensors).float()/25
valid_3_tens = torch.stack([tensor(Image.open(o))
for o in (path/'valid'/'3').ls()])
valid_3_tens = valid_3_tens.float()/255
valid_7_tens = torch.stack([tensor(Image.open(o))
for o in (path/'valid'/'7').ls()])
valid_7_tens = valid_7_tens.float()/255
train_x = torch.cat([stacked_threes, stacked_sevens]).view(-1, 28*28)
train_y = tensor([1]*len(threes) + [0]*len(sevens)).unsqueeze(1)
dset = list(zip(train_x,train_y))
valid_x = torch.cat([valid_3_tens, valid_7_tens]).view(-1, 28*28)
valid_y = tensor([1]*len(valid_3_tens) + [0]*len(valid_7_tens)).unsqueeze(1)
valid_dset = list(zip(valid_x,valid_y))
def mnist_loss(predictions, targets):
predictions = predictions.sigmoid()
return torch.where(targets==1, 1-predictions, predictions).mean()
def batch_accuracy(xb, yb):
preds = xb.sigmoid()
correct = (preds>0.5) == yb
return correct.float().mean()
lr = 1.
dl = DataLoader(dset, batch_size=256)
valid_dl = DataLoader(valid_dset, batch_size=256)
dls = DataLoaders(dl, valid_dl)
learn = Learner(dls, nn.Linear(28*28,1), opt_func=SGD,
loss_func=mnist_loss, metrics=batch_accuracy)
learn.fit(10, lr=lr)
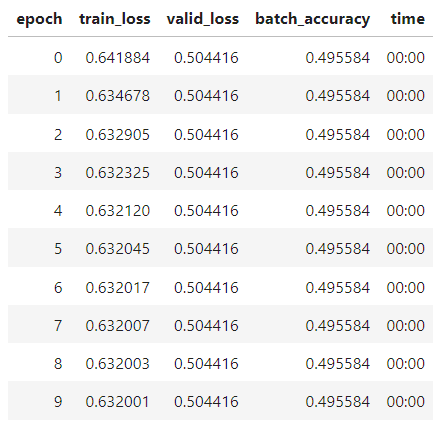
I tried to increase my learning rate. It doesn’t help at all. Instead, I find that decreasing the learning rate to 0.1 would make significant improvement to the model.
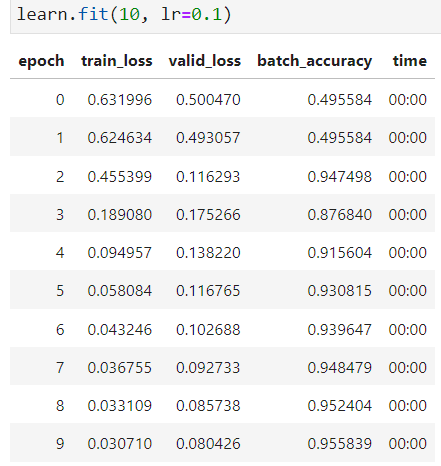
The batch accuracy jumps from less than 50% to 95% in the third epoch, which surprise me very much. Why do this happen? Is there something wrong with the code?