I cant get a model working which outputs more than one value. I use the column_data and structured parts of the library but I get errors like : input and target shapes do not match and boolean index did not match indexed array along dimension 0.
Processing the data using “proc_df” also was difficult with multipule values of y. It would be great if anyone could guide me.
Thank You
Can you provide more details of what you have tried and what doesn’t work? These errors are typical of not getting the input or output structure correct but its very difficult to help without more information.
So I have tried passing a list of targets to proc_df as a variable “target_vars”. Seems like proc_df doesn’t like lists so I just went into the source for proc_df and made that work for my use case.
However where I’m confused is where to indicate in the modeldata object or in the learner object that I have multiple targets.
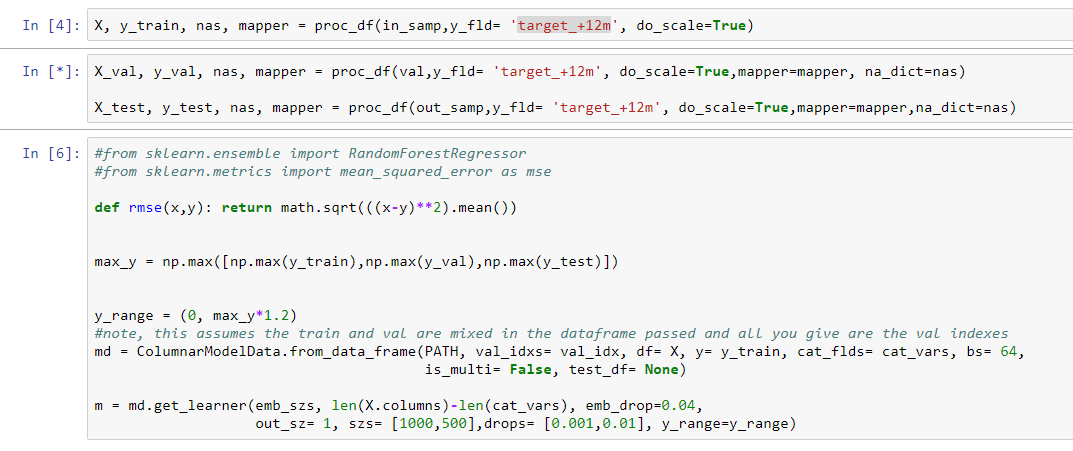
Here is a screenshot of my code which works for a single target. I’m trying to alter it to multi-output preferably with a higher weighting on a individual target within the multi-output target list.
so i guess i’m asking, is there a way to pass a list of targets to proc_df and I’m just doing wrong?
Do I need to do anything else besides is_multi= True and set out_szs to the len(list of targets) ?
What about for upweighting a given target in the list of targets, is that the wds parameter ?
Unfortunately I’ve deleted the sample code that had errors in it to focus on getting single output working. I will try again and post here when i have sample code for multi-output that fails.
For me I first found out that I could not pass a list to proc_df() as y_fld. I was able to fix that by running proc_df() multiple times on single y_flds and then combining all the resulting y values into a single array of shape (no of targets,no of rows).
Then I ran into a problem with from_data_frame() function which contained a function called split_by_idx(). split_by_idx() required the arrays to have the same dimensions in the first place. I fixed that by reshaping the y array to (no of rows , no of targets)
After that whenever I run a learn function on the learner object it gives me an error. the error is related to the pytorch loss function. It says :
input and target shapes do not match: input [128 x 5], target [128 x 1 x 5] at c:\programdata\miniconda3\conda-bld\pytorch_1524549877902\work\aten\src\thcunn\generic/MSECriterion.cu:15
My reading of this is that Proc_df should work ok if the variables are part of the dataframe and are of the right type, if this is the case I don’t see why passing a list of columns should not work. If the columns are numerical then it probably won’t since there is a flag in the routine to prevent this.
Are you doing regression or classification. If regression then you need to set the is_reg flag to True. Apart from that my understanding is that if you set is_multi then it will select the appropriate loss function and the output number of outputs will be se by out_sz. For binary cross entropy pytorch will expect one column per class in the y array.
At present I can’t see a convenient way to pass a set of loss weights into the criteria function although clearly Pytorch allows this and I have used it in the past in standalone (non-fastai) models. If anybody could shed light on wheher this is possible at present it would be helpful. I don’t think it would be too much work to add this as a feature but no point in doing so if there is already a way.
I got it working by setting is_reg to False. This made my y values the correct shape(no of rows , no of targets) instead of (no of rows , 1 , no of targets). is_multi is still set to True. Another thing i noticed was that the model started using log_loss instead of MSE.
Any chance you’d be willing to share your code for how you created your array of y’s (from proc_df) and then passed that to ColumnarModelData.from_data_frame? I’m having a bit of trouble working that out. Thanks much.
Thanks much - and how are you setting torney_df? I run into index errors when I try to set my test dataframe with multiple variables like you’ve done. Thanks again.
Thanks for all your help. For what it’s worth, I modified your approach slightly and have something that appears to be working though I need to do some more validation. Instead of passing the dataframe to prof_df multiple times (which didn’t seem quite right to me because then each time you are rescaling the dataframe) I just modified the proc_df function as such so it iterates through a array of y_flds and returns an array of ys then you can then reshape as appropriate to pass to the ColumnarModelData with is_multi=True. See my tweaked function below. I passed both the train and test datasets through this function as they did in the Rossman example.
def proc_dfs(df, y_flds=[], skip_flds=None, ignore_flds=None, do_scale=False, na_dict=None, preproc_fn=None, max_n_cat=None, subset=None, mapper=None):
if not ignore_flds: ignore_flds=[]
if not skip_flds: skip_flds=[]
if subset: df = get_sample(df,subset)
ignored_flds = df.loc[:, ignore_flds]
df.drop(ignore_flds, axis=1, inplace=True)
df = df.copy()
if preproc_fn: preproc_fn(df)
else:
ys = []
for y_fld in y_flds:
if not is_numeric_dtype(df[y_fld]): df[y_fld] = df[y_fld].cat.codes
y = df[y_fld].values
ys.append(y)
skip_flds += [y_fld]
df.drop(skip_flds, axis=1, inplace=True)
if na_dict is None: na_dict = {}
else: na_dict = na_dict.copy()
na_dict_initial = na_dict.copy()
for n,c in df.items(): na_dict = fix_missing(df, c, n, na_dict)
if len(na_dict_initial.keys()) > 0:
df.drop([a + '_na' for a in list(set(na_dict.keys()) - set(na_dict_initial.keys()))], axis=1, inplace=True)
if do_scale: mapper = scale_vars(df, mapper)
for n,c in df.items(): numericalize(df, c, n, max_n_cat)
df = pd.get_dummies(df, dummy_na=True)
df = pd.concat([ignored_flds, df], axis=1)
res = [df, ys, na_dict]
if do_scale: res = res + [mapper]
return res
Gotcha, I have 4 classification categories (1-4 in a single df column) which I’m one hot encoding into 4 different columns. When I try to create a ColumnarModelData object I get the error TypeError: only integer scalar arrays can be converted to a scalar index, which I’m assuming has something to do with the shape of y, but I can’t seem to get it into a shape it accepts. Any ideas?