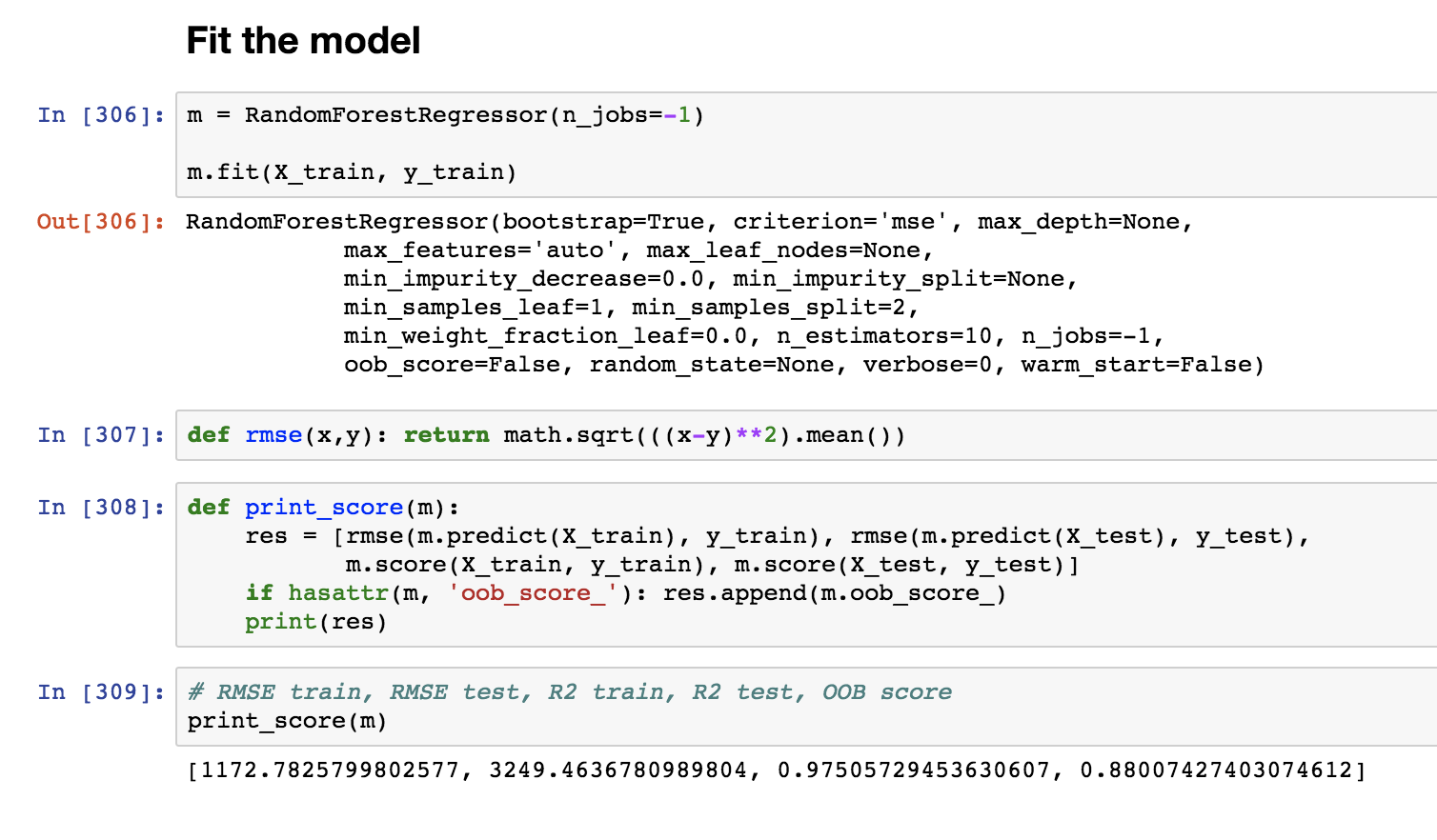
Then, I run a randomized search for hyperparameters using RandomizedSearchCV. Using the hyperparameters the random search returned, I fit a new model and get an R-squared on the training set of 0.94.
I see you haven’t tuned n_estimators which is one of the more important hyperparameters to tune…and also try gridsearchcv rather than randomsearchcv…as randomsearchcv is not exhaustive search but gridsearch is
Did you try hyperparameter tuning with only min_sample_leaf and max_features (not using max_depth and min_sample_split). Tuning max_depth together with min_sample_leaf could reduce accuracy as it limits the depth of tree (which is not always needed).
Better approach might be –
Tune n_estimators first.
grid search for min_sample_leaf and max_features with optimum n_estimators
n_estimators is the number of trees in the random forest. The more, the better, I don’t think you can really ‘tune’ the number of trees the same way you tune the other hyper parameters.
The ‘max_depth’ limits how far deep each tree can split. Limiting the depth of the tree could be useful to prevent the model from overfitting on the training data. But I think it’s really hard to justify a value for max-depth because, in combination with max_features < 1, it affects each tree differently. Might miss out on capturing some really interesting, deep relationships by limiting depth.
Min_samples_leaf is the minimum number of samples that must be contained at each leaf. This parameter can be useful against overfitting. Random Forests will continue splitting until each value of the training set can be properly ‘predicted’ by the tree. But setting a min number of 2, for example, will prevent the tree from splitting further if the split would produce a leaf below 2. So in this case, you can say that every leaf (terminal point) of a tree will contain 2 or more sample observations. I think choosing this parameter is data-dependent–but 2 to 5 is a decent start if you’re worried about overfitting.
I usually stick with tuning max_features and min_leaf_sample. When you start messing with many parameters, it’s hard to determine the optimal mix.
The other thing to mention is that, from my understanding, you should be more concerned with the scoring of your model on the validation set than the training set. In fact, having a r^2 near 1 on your training set could be indicating over-fitting to the training set, whereas the performance on the validation set (assuming that it is representative of your test set) is the more insightful value, indicating that you will perform well on the test set. Thus, performing a parameter search which maximizes scoring on a validation set may in fact reduce the r^2 on the training set. Therefore, the stranger aspect of your output is that the rmse and r^2 got worse on both the training AND the validation set after using RandomizedSearchCV.
As far as using these GridSearchCV/RandomizedSearchCV methods, you may find parfit useful, as it is a bit more intuitive on how the scoring works (directly uses whatever metric you enter, evaluated on the validation set), and comes with a visualization of the scores over the grid that you enter.