Hello.
I really need the community help here! i am stuck for more than a week!
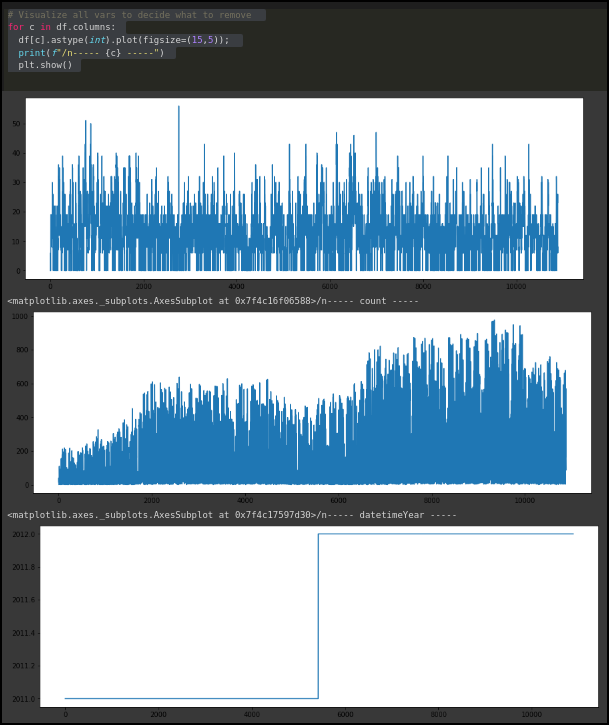
I’m working on my tabular data set.
My is in some way similar to Rossman (except Sales I am trying to predict air pollution).
My training data contains 12,711 samples. (my validation sets has 1700 samples).
when I try to train my model I get huge train_loss and valid loss:
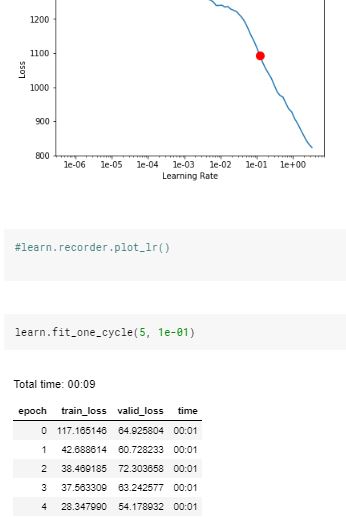
and it doesn’t get much better.
- after a few training sessions I predicted my parameter and I got predictions ~ 1,000,000 expect ~ 30-50. (in my units).
- if you need some more details I can give.
Thank you very much!
Offir Inbar