Hi @chansung18@muellerzr, thanks for your interest.
AFAIK, fasthug is fastai + huggingface / transformers, which get you model training and tokenizers (correct me if I am wrong).
And hugdatafast is fastai + huggingface / nlp, which get you Dataloaders.
You should be able to use hugdatafast with blur or fasthug. (Although I haven’t tried.)
Working on a blogpost/notebook using hugdatafast with blurr sometime this weekend (after I work through some PRs).
I think things should work out fine for the most part, though I’m not so sure about the use cases where post-processing is applied to the raw inputs to get things to line up right with the subword/BPE tokenization (I’m thinking things like question/answering and token classification/NER).
Update: add a example for preparing any hugginface/nlp dataset for (traditional) langugage model, or implement custom context window.
Update the update: I cancel the updates.
— Reason — (just for notes, skipping is ok)
Originally I want to introduce LMTransform and CombineTransform, which can do context window over examples. But I suddenly thought there is few cases we need context window across examples. Examples in a dataset are often not consecutive, we don’t need to concatenate texts not related. So these classes might be only useful for my personal use case.
I tried working up an example with blurr, but I failed
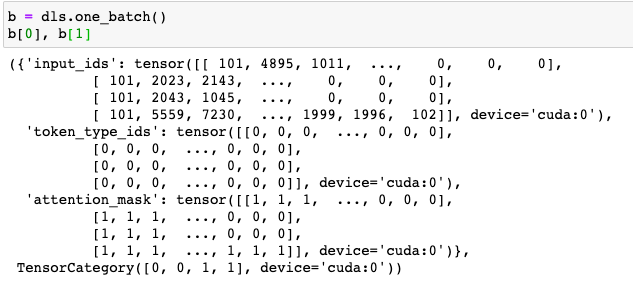
Maybe I’m missing something, but I think the problem is that the datasets/dataloaders returned from Hugdatafast only returns the “input_ids” … whereas blurr is designed to return (and work against) all the other things associated to a text sequence depending on the architecture (e.g., input_ids, attention_mask, token_type_ids, etc…)
So for example, here is what one batch of Hugdatafast looks like …
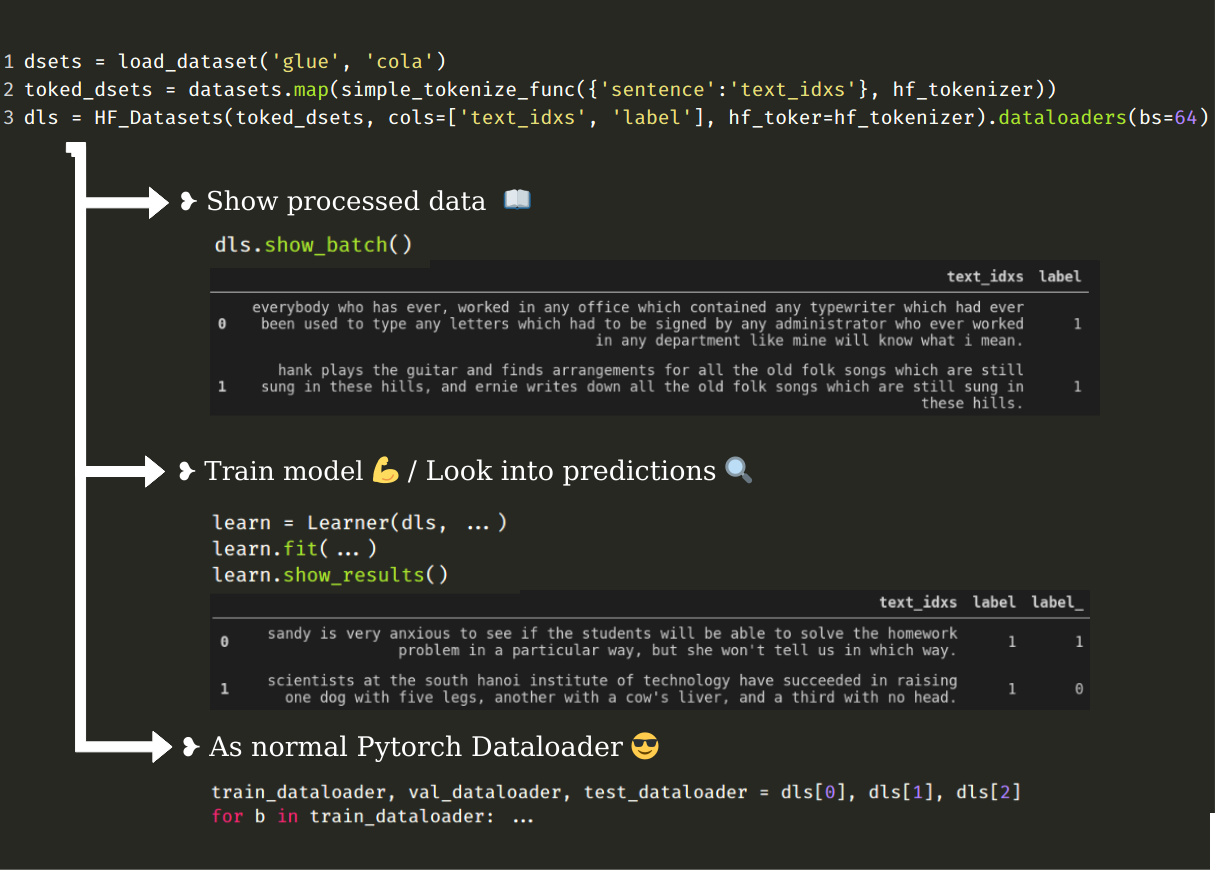
hugdatafast doesn’t provide built-in preprocessing, you need to map your hf/nlp dataset (write your own preprocessing logic) and then hugdatafast make the preprocessed hf/nlp dataset all the way to Dataloaders we are familiar with.
 fastai
fastai pip install hugdatafast
pip install hugdatafast Documentation: https://hugdatafast.readthedocs.io/en/latest/
Documentation: https://hugdatafast.readthedocs.io/en/latest/