@jcatanza
Having a setup on your own machine is a double edged sword. It is so very easy to get sidetracked.
In an effort to stick to the course work, I go back and forth between my rig and a paperspace setup. Jeremy had an exercise concerning bears and said we should acquire and load our own data. I had hours of pain trying to follow the process of getting urls of oaks, elms, and beech trees and loading them to paperspace. I was able skip all that and directly load my images on my home rig in about 15 minutes.
On other exercises, Wimpy runs out of memory and I have no choice but to use the rental.
Are you a live classroom participant or taking the courses online?
Both. I am reviewing Course 1v3 online and looking forward to the live classroom Course 2v3 beginning next week. I also have been using paperspace, but am frustrated by the unreasonable overhead to get connected, and the consequences of forgetting to close the session.
@abicz
After a bit of digging, I found some additional information (learned a lot).
I ran Task Manager and watched CPU and GPU utilization in the Processes tab. For all the exercises in Lesson 1, I saw CPU up around 100%. In one of the exercises, with one of the NN models (maybe resnet34) I’d see GPU utilization as high as 29% when a process named Python was running. In almost all other cases I’d see a much lower reading for GPU…maybe as high as 10%. I never saw Python as the Process name on any of the other lessens that I ran. This bolsters the observation that I read earlier that effective GPU utilization is a matter of software implementation.
Some time ago I found a utility called Speccy. It organizes and presents details about a PC that I didn’t know existed. I used it to monitor CPU and GPU temperature.
Even when Task Manager shows only 10% utilization, the GPunit temperature would go up to about 70 C (about 160F) from a bit over room temperature.
I know that Msft tools have been used by millions, but I wonder about the accuracy of the GPU info which Task Manager reports. TM was written long ago and GPU reporting is an afterthought. The TM Performance tab can sometimes be informative, too, but I have the same suspicion about accuracy.
I think if torch.cuda.is_available() comes back true, then you are probably getting as much bang for the GPU buck as is possible, from the driving software.
Wimpy has taught me another lesson. I had to experement but if I set bs = 2, I can run every lesson. I reliably get out of memory if I set the batch size bigger. It doesn’t seem to affect the results at all. Wimpy is a 1030 GT with 2G memory.
If you are resource constained…(or financially, like me) and go the cheap Charley route, you might be storage (c drive) constrained. You should consider putting things like dogscats, dogbreed, and weights (you know, everything you download after you git fastai and update conda env.
Don’t forget to defragment! The wimpier you are, the more it will affect performance.
@mike00
I monitor by Task Manager and seen 26% cpu utilisation, and I have 4 cores. I see only 5% utilisation of GPU. Also training time is 6 time slower then on the same GPU on linux.
@abicz
Without dredging through the details, it sounds like either the windows operating system or the Anaconda implementation on Windows is bogging something down. If you have an identical level of Anaconda in both environments, then I’d stick with Linix.
Another note about Wimpy (#396) above.
I didn’t just experiment. I had to do a lot of trial and error to get the learn steps to work without running out of memory.
I have a new problem, and don’t know if it is related to the batch size or if it’s a consequence of experimenting, but now this happens when I run 2018 lessen1 dogbreeds with resnext101:
Is there a parameter that should be reset when a lesson is rerun? I didn’t see this on paperspace, but I didn’t have the memory issue and didn’t have to run the lessons over and over.
I’m going to try to find something in the forums, but posting here in case anyone else has the same.
I reinstalled fastai as a workaround, but that doesn’t really solve the problem.
I have the same problem.
I’m using Fastai on Windows 10 and if I run learn.fit_one_cycle my computer seems only to use CPU and no GPU altough torch.cuda.is_available() is True and torch.cuda.get_device_capability(0) returns (6,1).
I tried torch.cuda.set_device (0)but it didn’t help.
if I type in python -m fastai.utils.show_install into an anaconda Prompt it shows me:
@Claus
It took some digging to convince myself that my GPU was actually being used. See my post, 406, above. I still suspect that Task Manager is not showing accurate utilization for GPUs. Get the windows app called Speccy and watch the graphics panel for the temperature while you run some training.
The only other possible answer is worth repeating: “…effective GPU utilization is a matter of software implementation.” In other words, you probably have to dig into the code behind learn.fit_one_cycle.
Hello,
I installed fastai on my windows 10 laptop and i got this error . The module fastai wasn’t found , i did create the shortcut in the course-v3\nbs\dl1 folder.
Any solutions?
Thanks
!
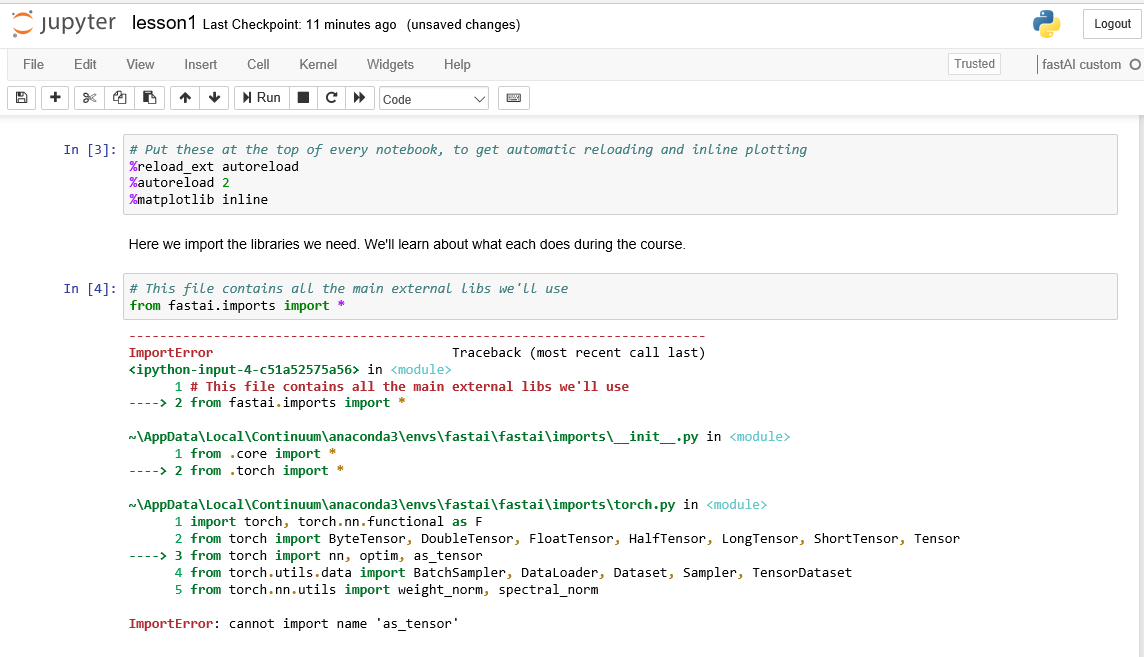
Hello,
Thank you for your great instructions. I installed fastai on win10 and got this error. ImportError: cannot import name ‘as_tensor’. I followed the instructions and did all the steps.
Any solutions?
Thanks in advance
Thanks a lot. I figured that out by adding sys. path. However, train_cats function doesn’t work in the first lesson under the machine learning category.
Edit: I copied the function from structured.py into transform.py. It works!