After trying out some libraries, I started to implement neural net from scratch. I have successfully implemented the fully connected network but I am stuck in gradient calculation for the convolutional layers. Here is a screenshot containing the architecture of the network. Please read the explanation regarding the screenshot to understand the details .
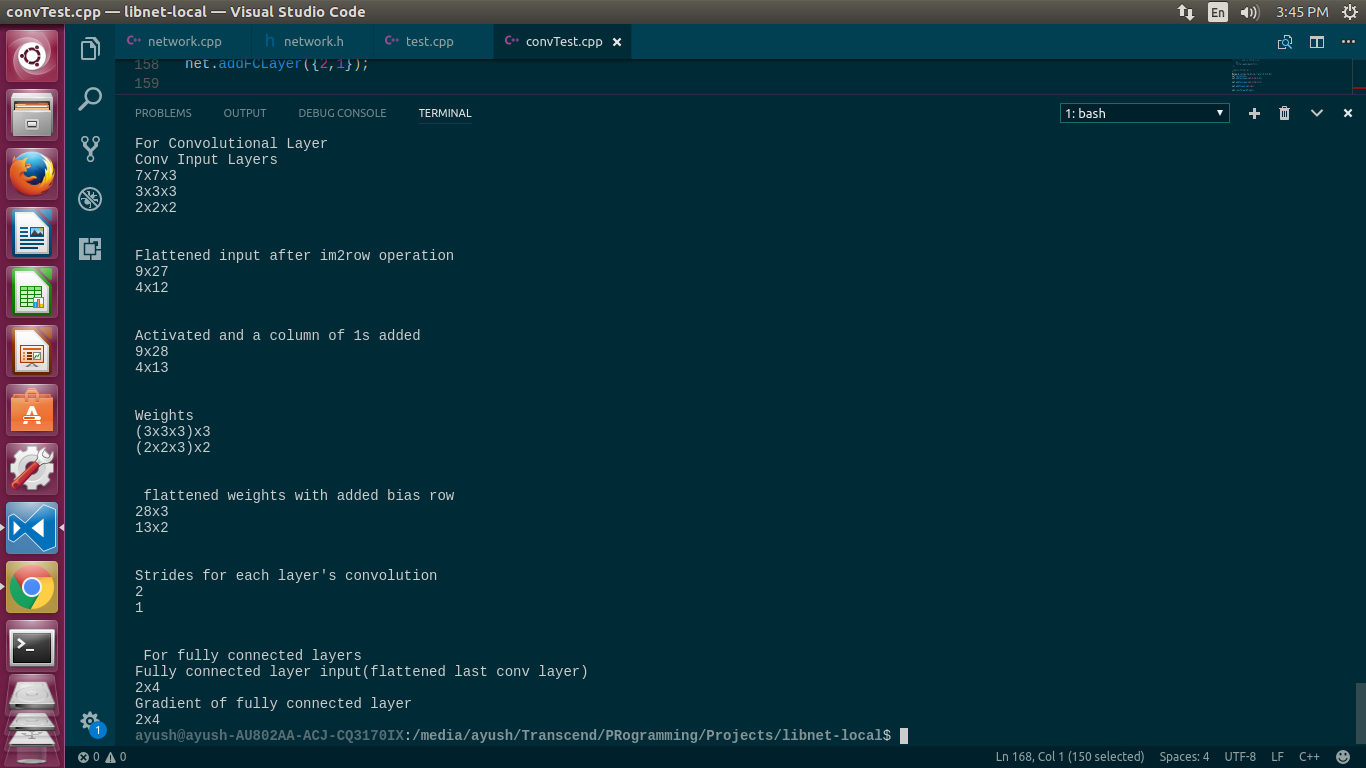
Conv Input Layers
The first convolutional layer is the input, the second layer is the result of convolution on first layer and the third layer is the resultant of second layer which is flattened and used as fully connected layer.
Flattened Input layer
resultant after applying im2row(similar to im2col but transposed) operation to flatten and vectorize the 3D convolution calculation.
Weights
It represents the filters used for convolution. There ‘n’ are 3D filters. So the dimension is of the form (axbxc)xn
Strides
it represents the stride used for convolution operation in each layer. The first layer uses 2 strides and thus the resultant layer(i.e. the 2nd layer) is of dimension mxmx3 , where m=(7-3)/2 +1 = 3.
Next, the last layer is flattened and converted to fully connected layer and its gradient(dX) will be of the same dimension.
But I don’t know how to vectorize the gradient the gradient calculation for conv layer. Theoretically the gradient of a layer is the convolution between its weights and gradient of next layer but to implement that, the flattened layers and filters must again be converted to 3D and then convolved. I have read about vectorized implementation of gradients but I just can’t figure it out. So considering that I have already calculated the gradient of fully connected layer proceeding the last conv Layer, how can I calculate the gradient for the conv layer with actually using convolution again ?
 This is great to know
This is great to know