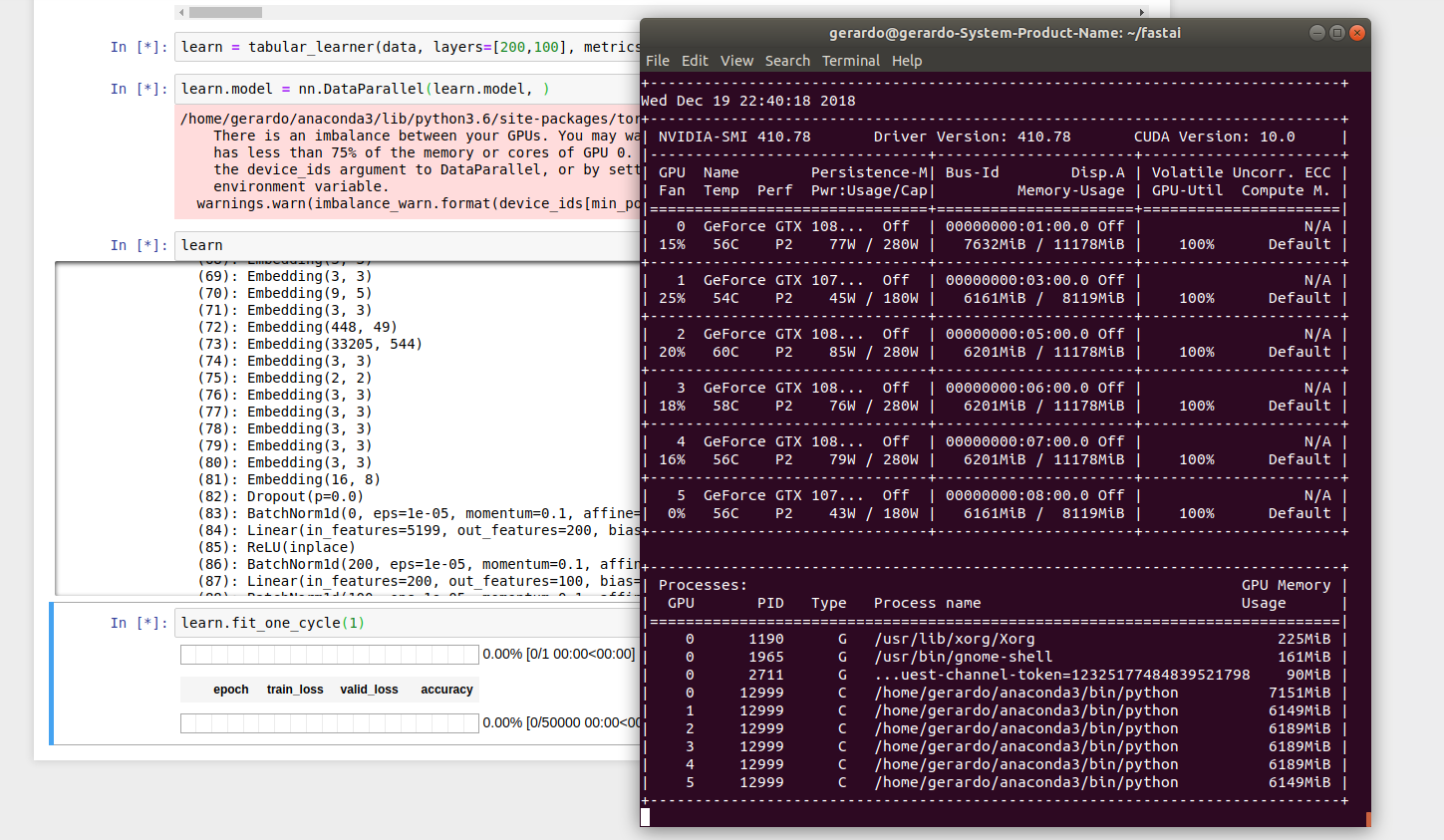
also @matdmiller:
In version 1.0.28, I tried comparing speed improvements doing your parallelization approach and altering batch sizes. The way I changed batch sizes was passing bs parameter during data creation for tabular model:
data = (TabularList.from_df(df, path=path, cat_names=cat_names, cont_names=cont_names, procs=procs)
.split_by_idx(list(range(n_split, n)))
.label_from_df(cols=dep_var, label_cls=FloatList, log=False)
.add_test(test, label=0)
.databunch(bs=1024))
I have two GPUs. The approach I used was this:
layer_groups_total = len(learn.layer_groups[0])
for i in range(layer_groups_total):
learn.layer_groups[0][i] = nn.DataParallel(learn.layer_groups[0][i], device_ids=[0, 1])
Then I timed training the model with
%%timeit
learn.fit_one_cycle(1, 1e-2)
Yet, the improvements in speed were barely, if at all, seen:
Using multiple GPUs, Batch size vs. run time:
- bs = 64: 5.91 s ± 571 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 128: 3.39 s ± 101 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 256: 2.35 s ± 89.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 512: 1.85 s ± 39.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 1024: 1.68 s ± 60.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Using single GPU, Batch size vs. run time:
- bs = 64: 6.09 s ± 743 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 128: 3.35 s ± 43.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 256: 2.44 s ± 83.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 512: 1.94 s ± 70.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 1024: 1.68 s ± 70.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Update:
I also tried parallelizing the entire model (instead of layer by layer approach above) with
learn.model = nn.DataParallel(learn.model)
However, during training with learn.fit_one_cycle(1, 1e-2) I get RuntimeError: CUDA error: out of memory at the same batch size (2048) that I successfully use for single-GPU computations. When I reduce my batch size by half (down to 1024), fitting works, but at twice the lower speed as before at the same batch size of 1024:
-
At bs = 1024
- two GPUs:
2.98 s ± 193 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- single GPU:
1.68 s ± 70.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
-
At bs = 2048
- two GPUs:
RuntimeError: CUDA error: out of memory
- single GPU:
1.66 s ± 71.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
It looks to me that using two GPUs, then, is not beneficial, at least in my case.
Update 2
Here are more comprehensive results with and without using learn.model = nn.DataParallel(learn.model):
Using multiple GPUs, batch size vs. run time:
- bs = 64: 14.2 s ± 205 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 128: 8.08 s ± 61.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 256: 5.17 s ± 101 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 512: 3.77 s ± 50.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 1024: 3.03 s ± 61.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 2048: CUDA error: out of memory
- bs = 4096: CUDA error: out of memory
Using single GPUs, batch size vs. run time:
- bs = 64: 6.09 s ± 743 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 128: 3.35 s ± 43.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 256: 2.44 s ± 83.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 512: 1.94 s ± 70.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 1024: 1.68 s ± 70.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 2048: 1.73 s ± 14.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 4096: CUDA error: out of memory






 ️.
️. But I think we’ll improve as we get more experienced.
But I think we’ll improve as we get more experienced.