First of all, thanks for your help, I really appreciate it !
Here’s the information about the dataset.
Number of images:
- training set: 580 images
- validation set: 70 images
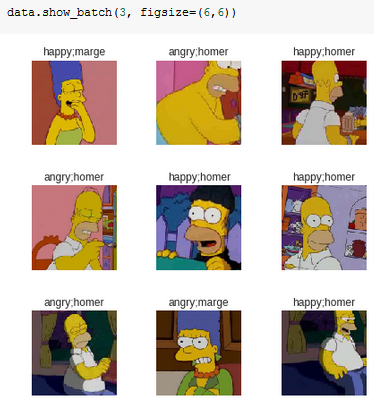
Both the training and validation images are contained in a single folder.
- I’ve used a text file to identify the images of the validation set.
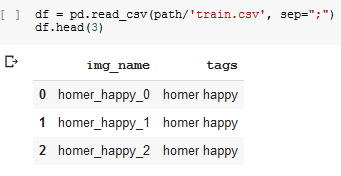
Labelling - I’ve tried to use the same labelling system as the one in the planet dataset:
- a csv file, with 2 columns:
- column 1: contains the images’ names
- column 2: contains the labels
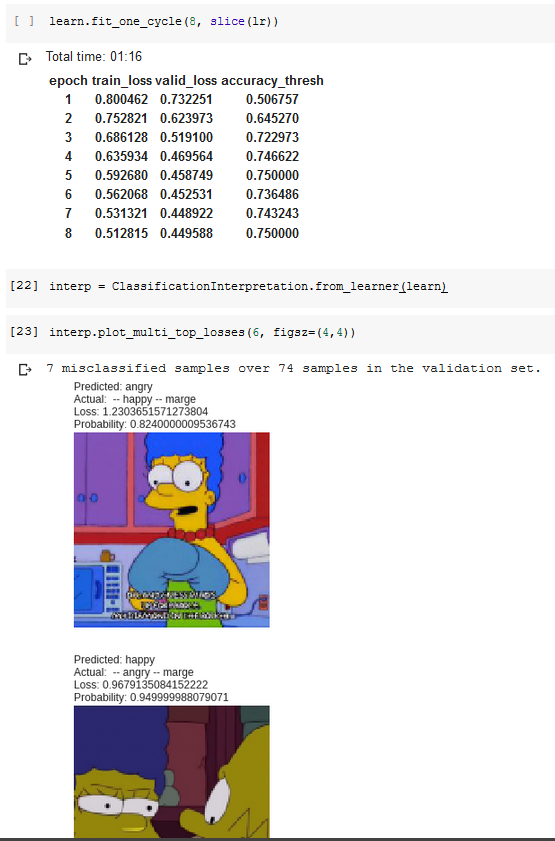
I’ve tried to rerun the training process and plotted the results: the model seem to have only predicted the expression
Let me know if you need anything else. Thanks again.