Hello,
I’m following the course and I noticed how all the images used to train a model are of very small size, so I was wondering what techniques could be applied in order to make it feasible to train models with very high resolution images. I work in the film and video industry and I would love to be able to apply what I’m learning on some problems regarding my field, but all images are at the very least 2k or 4k format.
For example a segmentation like the one shown in lesson3 is still great but pretty useless on 4k images because of the lack of fine details
Not for segmentation but for classification, I am working on (really very) large images by extracting tiles of a reasonable size and then combine results.
Thanks Vincenzo,
this is kind of what I had in mind but I’m not fully grasping how (even for classification) this approach can work.
My doubt is the following: how is the classifier going to understand that it is looking at a dog when every tile only looks like a bunch of noise?
Like, how can I understand I’m looking at a steak if I’m observing small portions of it under a microscope?
If the steak is as large as your image, you can just resize it, no need for very large resolution.
If your images contain many fine details, you may choose a sensible tile size comparable with the size of objects that influence classification, and of course have some overlap.
I understand.
And are you breaking the image into tiles on a separate software or did you write a function that does it inside python?
In that case would you mind sharing the tiling procedure?
ImageJ (and I am also so lazy that the code is too horrible to be shared  )
)
 I understand! thanks for the tips, much appreciated
I understand! thanks for the tips, much appreciated
I like using a couple of strategies:
-
In segmentation problems I clip images along the edges of the object. I make a rolling window go through the image and calculate the ratio of how much of the object is in the window, and clip the image when the ratio is enough. For example, in the Carvana car dataset I wanted to have at least 25% and at most 75% of the image covered by a car.
-
In classification we don’t have masks so we need to create our own. I train the model on smaller resized images first and then get heatmaps of the areas of interest in the image. I then use these areas of interest the same way as in segmentation and clip parts of the original large image which containt the interesting points. Below on the right side is the heatmap and on the left are the points with highest values in the heatmap.

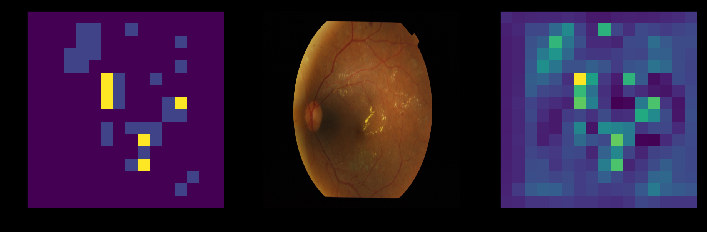
Naturally, these don’t fully solve the problems of working with massively large images and especially the 2. method is veeery slow so I’m not sure if they are applicable in your domain.
Thank you for your reply,
very interesting strategies
Hi! I have a similar question regarding this topic, where rescaling the image to 224x224 is not enough for the CNN to pick up small details. From the discussion in this thread, it sounds like I should cut the images into smaller tiles and then train using those tiles.
My question is, how would prediction happen? For a given test image, if it has been split into, say, 4 tiles, but the predicted labels for the tiles are all different, how do you decide which is the correct overall prediction for that original image?
I think you may choose the strategy to assemble results. In principle, I would choose the top prediction, but, since details are small, you have to consider the possibility that the image represents more than one object. In this case, more than one label applies.