I have been thinking about whether a computer can do math like a human without using the computing component(e.g. CPU). So I tried to build a Neural Network to do simple math like plus, multiply, and square.
It turned out that the model can do ‘plus’ efficiently without overfitting, though the predictions for the test set that was out of the range of the training set was not as accurate as I expected.
However, I found that it’s really hard to fit a quadratic function (y = x^2) with Neural Network. I randomly generate 1000 numbers for input X, and calculate Y simply with the square of X, then fit the data into a NN model with 2 hidden layers. I tried several hyperparameters and normalizations but the model still could not make a satisfying prediction.
Did anyone try this successfully? What I expect was that after training the NN model will become very close to a quadratic function in all range of numbers.
Here is what I thought when I start this test: if a NN model can’t even learn a simple quadratic function, how can we trust it will do other things right?
But have you try for a test set that is out of the range of training set? Say, try X_test for [-4,4], and see if the model still can predict the corresponding results.
I like your question! If it can’t even do this, why trust it to do that?
In trying to understand RNNs better, I asked the same kinds of questions. In the end, it successfully fit combinations of x, e^x, sine, and randoms. But only after many struggles. For a while, the LSTM could not even learn to pass the same number out as in (identity)!
A math fact (I think!) is that polynomials can’t easily be approximated by compositions of linear and ReLU. So I am not surprised that the model has difficulty. Such problems are better suited to classic curve-filtting methods. That said, it is interesting to investigate and understand what deep learning models can and can’t do.
A few ideas:
Use a smooth activation function between layers. It’s hard to see how linear + ReLU could easily emulate a polynomial, even though I understand it’s theoretically possible. It may need more layers too, so that compositions of linear and activation can approximate x^2.
Try a simpler model. I found that if the model is too smart, it memorizes the training set and predicts badly. A model with less capacity is forced to generalize.
Are you predicting within the training domain or past the domain? This can distinguish between memorizing training points vs. failing to generalize a function.
What do you mean by “normalizations”? Make sure that the normalizations are not throwing away information that the layers need to approximate x^2.
You could fit ln() of input to ln() of target to solve x^2 in one layer. This is an example of using a “classic method”.
Good luck with your experiments. I would be very interested to know what you discover!
You can’t tell.
If you train with noisy data around -.1 and +.1 both:
A) y=x
B) y=sin(x)
Can be possible real distributions.
So you can have very good train performance, but at inference time on a larger domain (-4,+4) if (A) is the real distribution and you’ve select a linear model you’re ok, otherwise you’ll get very bad results.
The network will only work in the same range you have shown it. Why? Cause you are stitching together many linear functions(ReLU) to approximate the curve. The appropriate relus are added in the train interval but far away from that, the model has not done anything to that space. I touch over the x**2 approximation in my blog: https://bluesky314.github.io/perceptrons/, from the ReLu pics you can see that the last ReLU line will go on to infinity so, outside that trained range, the slope is a constant instead of 2x
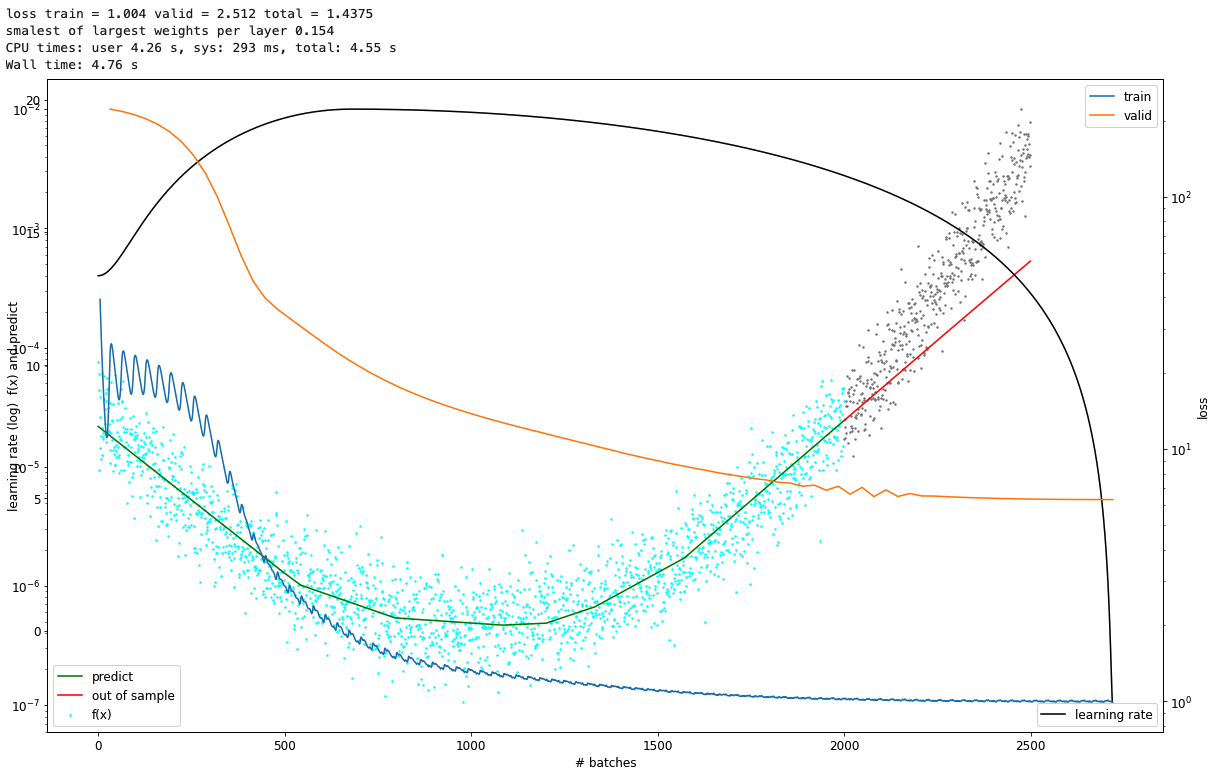
I figured out, that my first problems were nearly 1e-38 values in model.parameters() in one layer. So, use a small learning rate, 1Cycle method adaptive learning rates and check the model.parameters() if the model is broken or not - that should do the trick - attached my records smashed with f(x) and model predictions in one plot