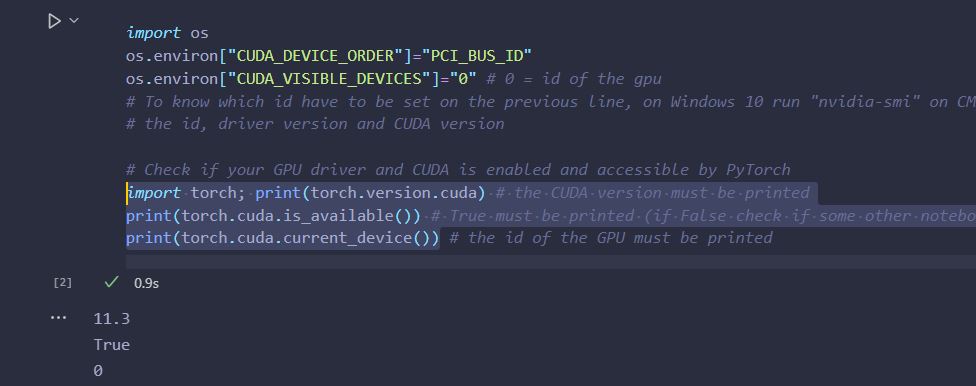
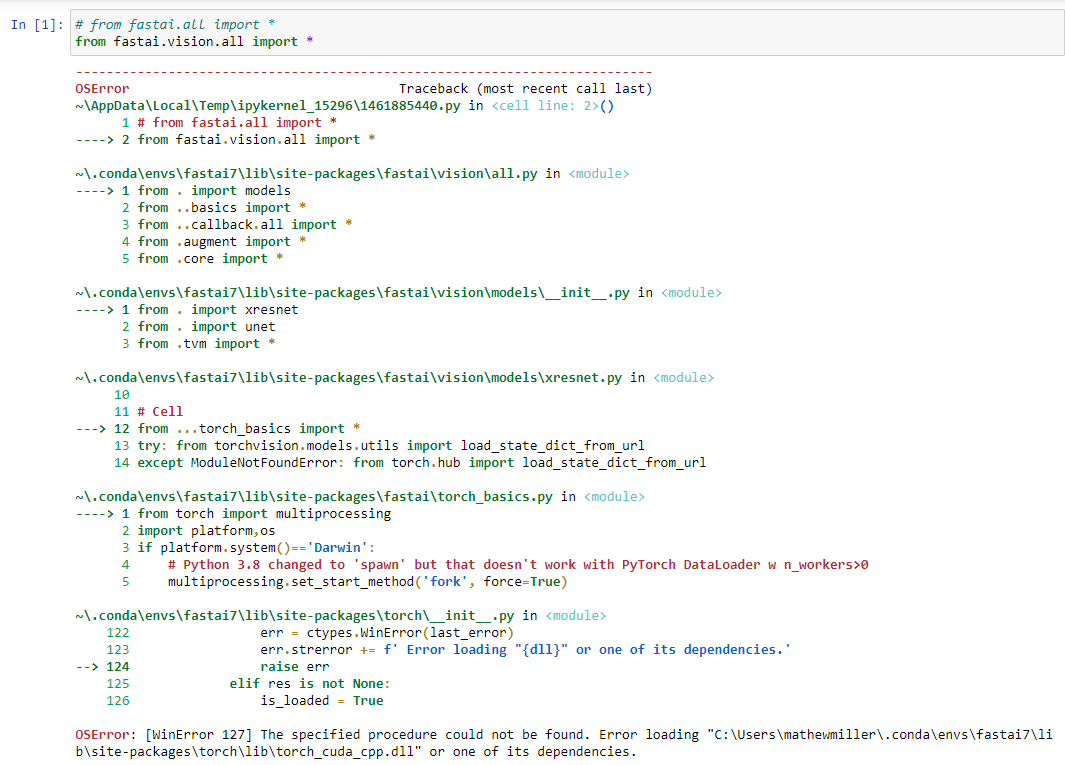
Hello everyone,
I’m running a Jupyter Notebook file locally with VS Code on Windows 10. I’m developing my first ever project using Deep Learning to train a Lung Detector model.
The issue I have is that when I run the function fit_one_cycle() the training is too slow and I hear noise on the PC. After 44min of execution of the function and completing 25 of a total of 100 epochs there 's still expected 2h29min more left to finish the execution.
Previously, the execution of the function learn.lr_find() took 14min to end.
Checking the Task Manager of Windows I figured out that the notebook wasn’t being executed on my GPU, instead it was executed on the CPU because the CPU use was at 70% and the GPU at 1-3%.
I’ve also executed the function “torch.cuda.is_available()” following tutorials and the function returned False as you can see on the next image. But I’m only using PyTorch to use the L1Loss function.
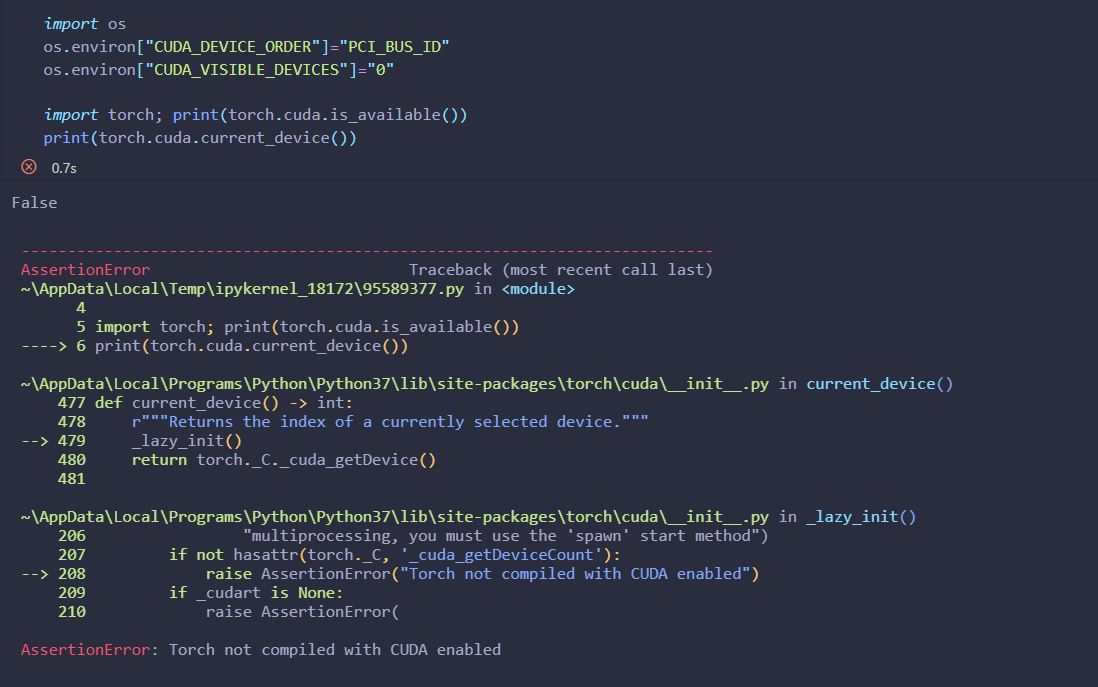
My GPU is a Nvidia GTX 1060 6GB. While running the lr_find() function I’ve run the command “nvidia-smi” on CMD to check the CUDA version of the GPU and the active processes. The results have been the following:
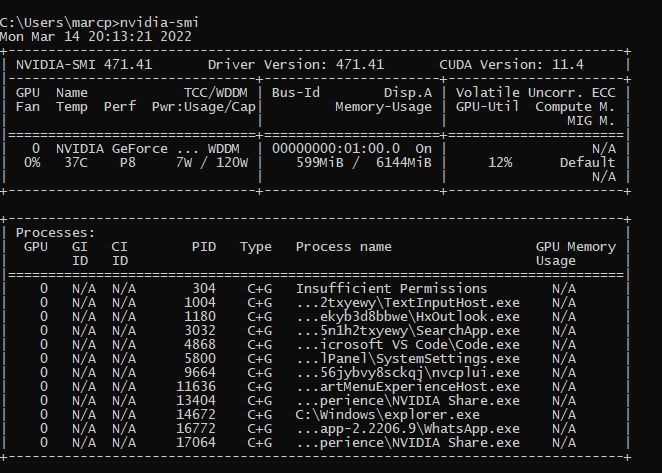
I don’t know what do I need to change of the notebook’s code or if I have to re-install fast.ai with CUDA to be able to run on my GPU at least the complex functions of the notebook such as fit_one_cycle.
I post the key parts of my notebook at the end of this post.
I would appreciate any suggestions on how to solve this problem.
Thank you.
Notebook’s Code
%reload_ext autoreload
%autoreload 2
%matplotlib inline
import os
os.environ[“CUDA_DEVICE_ORDER”]=“PCI_BUS_ID”
os.environ[“CUDA_VISIBLE_DEVICES”]=“0”
from fastai.vision.all import *
from fastai.vision import *
from torch.nn import L1Loss
import cv2
from skimage.util import montage
data = DataBlock(
blocks=(ImageBlock, BBoxBlock,BBoxLblBlock),
get_items=get_image_files,
n_inp=1,
get_y=get_y,
splitter = RandomSplitter (0.1),
batch_tfms= [*aug_transforms(size=(120,160)), Normalize.from_stats(*imagenet_stats)]
)
dls = data.dataloaders(path_dl, path=path_dl, bs = 64) # bs: how many samples per batch to load
dls.show_batch(max_n=20, figsize=(9,6))
class LungDetector(nn.Module):
def init(self, arch=models.resnet18): # resnet18 has 18 lineal layers
super().init()
self.cnn = create_body(arch) # cut off the body of a typically pretrained arch
self.head = create_head(num_features_model(self.cnn), 4)
def forward(self, im):
x = self.cnn(im)
x = self.head(x)
return 2 * (x.sigmoid_() - 0.5)
def loss_fn(preds, targs, class_idxs):
return L1Loss()(preds, targs.squeeze())
learn = Learner(dls, LungDetector(arch=models.resnet50), loss_func=loss_fn)
learn.metrics = [lambda preds, targs, _: IoU(preds, targs.squeeze()).mean()]
learn._split([learn.model.cnn[:6], learn.model.cnn[6:], learn.model.head])
learn.freeze_to(-1)
learn.lr_find()
lr_max = 1e-2
%time learn.fit_one_cycle(100, lr_max, div=12, pct_start=0.2) # find this function at schedule.py of callbacks dir (div_factor is obsolete)