Hey fastai people,
I have been trying to setup my recently bought macbook, and thinking to start with the Deep learning course through my local setup. I tried Paperspace, but their free GPU has been out of capacity for quite some time now whenever I checked (since the last 12–15 days). So, I thought, since M2 comes with a GPU, why not use that instead of buying/renting on cloud. Can someone pls help me in providing instructions on how to setup fastai & pytorch (GPU) on M2 Mac.
1 Like
I’ve written a guide on how you can use your M-Series GPU with PyTorch.
In a nutshell, you need to specify the device parameter as 'mps' or use the to method and pass to it 'mps' on whatever object you want to use on the GPU.
fastai has a default_device function which you can use instead, by calling it at the beginning of your code and passing into it 'mps'. It removes the need to use device parameter or the to method.
That said, for this course, I’d recommend using a cloud GPU (try Kaggle or Google Colab) instead of an M-GPU. Certain things work on an M-GPU while others don’t because of support. However, I’ve found working with tabular models works fine and is relatively error free.
3 Likes
As of today it seems that M1 Macbook Pro seems to work with GPU acceleration out of the box.
Seriously, the setup couldn’t be easier.
pip install -r .devcontainer/requirements.txt
Is all I needed to do in a pyenv installed python 3.10.
Here are the training times from an unmodified 02-saving-a-basic-fastai-model.ipynb.
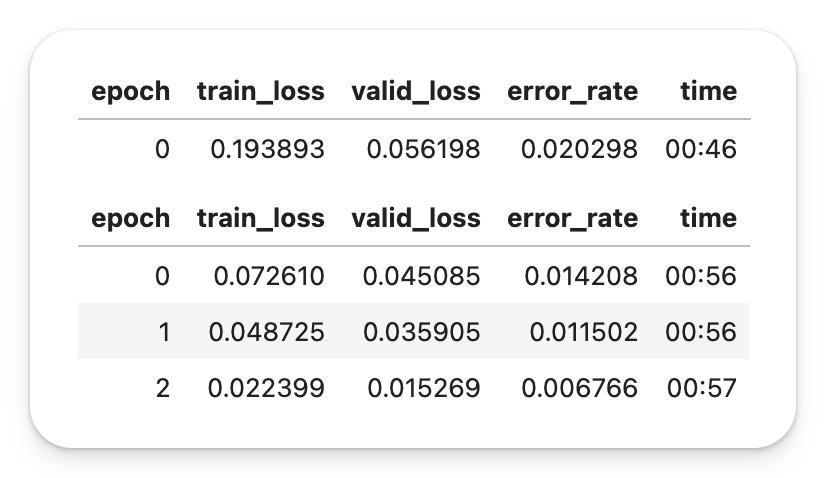
And here is the same on a Kaggle P100 GPU
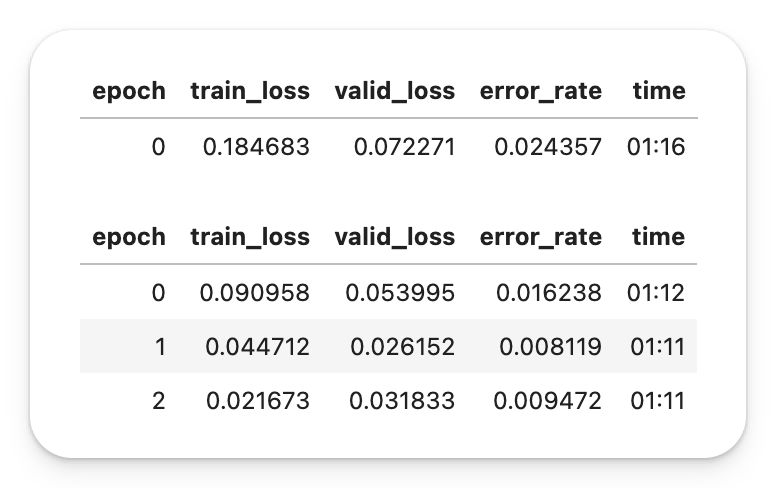
I don’t know how will it be on later examples, but it seems that at least this example works out of the box as of today.
1 Like
Is there a way to use mps for the hugging face Beginner NLP project for chapter 4?
I tried following your instructions and disabling fp16 to get past an arm64 support error TrainingArguments throws.
args = TrainingArguments('outputs',
learning_rate=learning_rate,
warmup_ratio=0.1,
lr_scheduler_type='cosine',
fp16=False,
evaluation_strategy='epoch',
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size*2,
num_train_epochs=epoch_count,
weight_decay=0.01,
report_to='none')
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=1)
device = torch.device("mps")
model.to(device)
trainer = Trainer(model,
args,
train_dataset=ds_dict['train'],
eval_dataset=ds_dict['test'],
tokenizer=tokenizer,
compute_metrics=corr_d)
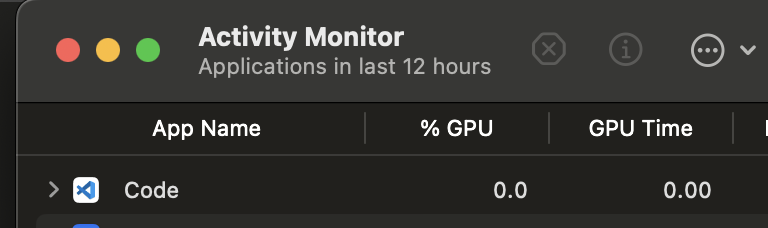
But my training still runs solely on the CPU according to OSX’s ActivityMonitor
I’ve never had success running Hugging Face on an M-Series GPU, mainly due to compatibility issues. That said, it has been quite a while since I have done so.
The process you want to check in Activity Monitor is not VS Code, but Python. The Code process is simply responsible for running the editor while the Python process will be the actual process running the code.
If that process still isn’t using the GPU, try using the default_device function from the fastai library. It sets all models to use whichever device you specify so. So in this case, run default_device('mps') before running anything else.
1 Like